Why websites crash due to high traffic & how to prevent it

How does high traffic actually crash an ecommerce website or app? Most people know websites crash when they're too busy. But few understand why, and how these crashes can be avoided. Discover the mechanics behind a website crash, common situations where traffic brings sites down, and 6 steps you can take to avoid ecommerce website crashes.
Surging online traffic is a dream for any ecommerce director. More traffic means more customers and more sales.
But website traffic can be too much of a good thing. You can become a victim of your own success.
If you don’t take proactive steps to address performance, spikes in online traffic can cause websites or apps to slow down and ultimately crash.
And the costs of these website crashes and slowed load speeds are staggering:
- 91% of enterprises report downtime costs exceeding $300,000 per hour
- 60% of customers are unlikely to return to a site if they encounter an error
- 2 out of 3 customers bounce if a site takes more than 6 seconds to load
At Queue-it, we help some of the world's biggest businesses stay online on their busiest days—from Ticketmaster to The North Face to Zalando. Our virtual waiting room has enabled thousands of organizations to overcome the nightmare of a website crash on their most important days.
In this article, we'll draw on our 10+ years of expertise to reveal how high online traffic crashes websites, common ecommerce situations that lead to crashes, website crash due to high traffic examples, and expert advice on how to avoid a website crash or slowdown during big sales.
Table of contents
There are many reasons why websites can crash. Most are within your control and preventable, but some are out of your hands. Causes of website crashes include:
- Human error: Like when a typo at Amazon took out a backbone of the internet.
- Network failure: Like when a DDoS attack on DNS provider Dyn caused dozens of top websites to go dark.
- Downtime of hosting partners: Like when roadwork damaged a fiber cable to a service center on Black Friday, causing outages at over 2,000 Danish websites.
- Malicious attacks: Like when over 70 Ukrainian government websites crashed after an onslaught of cyber-attacks in 2022.
- Traffic surges: Like the 40+ retailers that experienced crashes and slowdowns due to heavy traffic during Cyber 5 in 2021.
Of all these potential causes, a website crash due to high traffic is the most frustrating and costly.
Website crashes caused by high traffic stem from doing your job too well.
Imagine the frustration at Coinbase when their Super Bowl ad was so successful it crashed their site. That one-minute ad put them in front of their biggest audience yet, likely cost them upwards of $10 million, and when customers went to their site they saw… well, this:

RELATED: The 8 Reasons Why Websites Crash & 20+ Site Crash Examples
This is an all-too-common story for ecommerce sites. Website crashes due to high traffic occur during big sales, product drops, PR appearances, and successful marketing campaigns.
In short, high traffic crashes occur on (and ruin) your biggest days. They let down the most customers, lose the most sales, and, worst of all, are the most preventable.
Let’s look at how these crashes happen.
Take control of your traffic with a virtual waiting room to prevent crashes & slowdowns

Busy websites crash due to a mismatch between traffic levels (too high) and the capacity of the website’s infrastructure (too low).
Site visitors create system requests—adding products to carts, searching for products, inputting passwords—that exceed the processing capacity of your servers and/or any third-party systems involved in the visitor journey.
When this happens, your website will slow down, freeze, or crash.
Simply put: busy websites crash because insufficient resources lead to system overload.
The GIF below explains the concept in its simplest form. Too many site visitors are doing too much on your site for your infrastructure to handle—so it collapses.

This doing too much point is important. If visitors just sit on a cached home page—like if the marbles in the GIF just sat still—the site is likely to be fine.
It’s the system requests—like the jumping up and down—that bring the site crashing down.
“When there was a really huge spike in traffic ... we went from 0 calls one second to 1,000 the next. This means the cache didn’t have time to load, and our backend was overloaded. Some visitors encountered errors. It wasn’t a great user experience.”
THIBAUD SIMOND, INFRASTRUCTURE MANAGER
So, an overabundance of system requests crashes a website. Sounds simple enough, right? But there’s more to traffic-induced crashes than just that.
Not all requests are equal. Some requests are more complex or demanding than others. And the patterns of requests are just as important to understand as quantity.
This is why thinking of site capacity in terms of concurrent users just doesn’t cut it. 10,000 people on your site could crash it, but it could also be fine. It depends what these people are doing.
To explain, we’ll depart from our analogy of jumping marbles and take a trip to the supermarket.
The typical supermarket can hold a few hundred people, so long as they’re spread throughout the store. Let’s say 200. These 200 people meander about choosing their groceries. Some are in the frozen goods aisle, some in produce, others at the deli.
As people finish their shopping, they head to the checkout to bag their groceries and pay. Of the 200 in-store, there’s about 10 people who can be served per minute, and 10 people who enter the store per minute.
This works well. The cashiers serve customers, keep their lines moving, and the supermarket runs smoothly.
But imagine if all 200 shoppers rushed to the checkout counter at the same time. The number of shoppers in the store hasn’t changed. But suddenly the cashiers are overwhelmed. It’ll take them 20 minutes to clear out the 200-strong line.
Now, what if the number of people in store changes too? Imagine a sudden stampede of 800 new customers.
Everything’s been thrown off balance. The lines grow longer and longer. The store becomes overcrowded. Customers are frustrated and staff don’t know what to do.

This supermarket is a lot like an ecommerce site. Your site and its pages are like the aisles of the supermarket—people move around, browse, read product information. These are simple requests your site can probably handle.
But as customers on your site add items to their cart and go to check out, the requests get more complicated and demanding.
Your database must check inventory, verify their password as they login, call on a third-party plug-in as they type in their address, check their card details with your payment provider as they pay, send out confirmation emails, forward information to the warehouse, and more.
These more demanding requests are like the more demanding requests of the cashiers at the checkout of our supermarket. They need to kindly greet customers, scan and bag every item, field questions, and give out receipts. They can only do this with one customer at a time.
Both the cashiers at the supermarket and the complex requests on your site are what’s called a bottleneck. Bottlenecks are points of congestion in systems that slow or stop progress.
Bottlenecks are points of congestion in systems that slow or stop progress.
Like the mad rush of people in and out of the supermarket, high online traffic puts pressure on your site’s bottlenecks. And it’s these weak links, these points of congestion, that serve as limiting factors on website capacity.
Common ecommerce bottlenecks include:
- Payment gateways: The capacity of third-party payment providers is often out of your hands and can’t be scaled up.
- Database calls: Showing dynamic product availability to thousands of customers at once can often means more strain than your system can handle.
- Performance-intensive features: Features like advanced search, logins, and personalized recommendations are heavy drains on computing power.
- Synchronous processes: Processing payments, updating databases, lodging the order, sending out confirmation emails—trying to achieve all these in one fell swoop as customers check out can cause major issues.
It’s bottlenecks like these that often cause sites to crash. While these bottlenecks can manage your usual amount of traffic, when traffic suddenly surges, they get overloaded and bring your system down.
You’re only as good as your weakest link. So how much traffic a website can handle comes down to how much traffic its bottlenecks can handle.
RELATED: 2 Hazardous Bottlenecks that can Crash Your Ecommerce Website
That’s why distribution of traffic is key to preventing website crashes due to high traffic. Distribution of traffic avoids overloading points of congestion. It keeps the flow of customers in and out of the site steady and things running smoothly.
When a site crashes, it stops serving data to visitors. Your site becomes unresponsive, and visitors are unable to access its content.
Your servers’ job is to “serve” visitors your site’s dynamic content and handle their requests. They provide the computing power to check and update inventory when customers browse products and “add to cart”, and process payments and verify account details when they checkout.
But when your servers fail, customers find an unresponsive site, and leave frustrated.
That’s what happens when a website crashes from the visitors’ perspective. But to understand what’s happening behind-the-scenes, let’s look at a real-world example of a site crash caused by high traffic. (If you’re looking for a technical discussion from a developer’s perspective, check out Website failure under load? This is why).
Meghan Markle, the Duchess of Sussex, has a knack for causing websites to fail. It’s known as the Meghan Effect.
Markle has a devoted group of followers who pay close attention to everything she wears. Her fashion choices crashed an online retailer’s site not once, not twice, but three times
Let’s look at a customer journey to uncover just some of the behind-the-scenes legwork the site’s database is doing.
| Step Nr | End-user action | Request(s) |
|
1 |
Sees Tweet about dress, clicks on link to home page |
Loads images and browser script |
|
2 |
Types name of dress into search bar |
Complex search function must find all items that match search term(s), accounting for misspellings, product categories and features, etc. |
|
3 |
Browses list of products from search and clicks the dress |
Loads images and browser script. Shows up-to-date inventory (size, color) information. |
|
4 |
Adds dress to cart |
Inventory system must update to avoid overpurchasing and stay fully in sync for all other users |
|
5 |
Proceeds to purchase by creating guest account |
Sync dynamically-entered information with membership database |
|
6 |
Enters shipping information |
Send and receive requests from shipping plugins, like address verification and shipping costs calculator |
|
7 |
Enters payment information |
Send dynamically-entered information to payment gateway and await payment confirmation |
|
8 |
Sees order confirmation |
Inventory system updates stock remaining |
Each customer finding and purchasing a dress in this scenario creates at least 8 requests of varying levels of intensity. And the Meghan Effect means there are thousands of visitors performing these 8 requests all at once.
What’s more, there are several systems behind-the-scenes processing all these requests—the inventory database, the payment processing system, other third-party plugins.
Each step in the customer journey adds strain to site infrastructure. Eventually bottlenecks appear where processing power is fully extended, and additional requests cannot be served.
Website visitors experience this failure in the form of a website that slows down and eventually crashes, returning dreaded 503 error pages.

When overwhelming traffic swamps your infrastructure, the weakest link in the system will set the capacity of the entire system. And the dominoes start to fall.
There are three main scenarios where high traffic crashes websites and apps.
The unexpected traffic spike is when traffic surges due to factors out of your control. The Meghan Effect is an example. The retailers were unaware Meghan would step out in their apparel that day, and unaware of the rush it would cause.
These unexpected spikes can also come from a feature on primetime TV, sudden bot traffic, a viral social media post, or an unexpectedly successful marketing campaign.
Unexpected crashes are sometimes called the "Slashdot effect", which stems from the early 2000s when technology news site Slashdot would link to smaller sites, frequently causing them to crash. If a site unexpectedly makes it to the front page of Reddit and crashes due to traffic overload, it's called the "Reddit hug of death".
When France’s 3rd largest online marketplace, Rakuten, for example, appeared on the national news, their traffic spiked 819% in just 2 minutes.
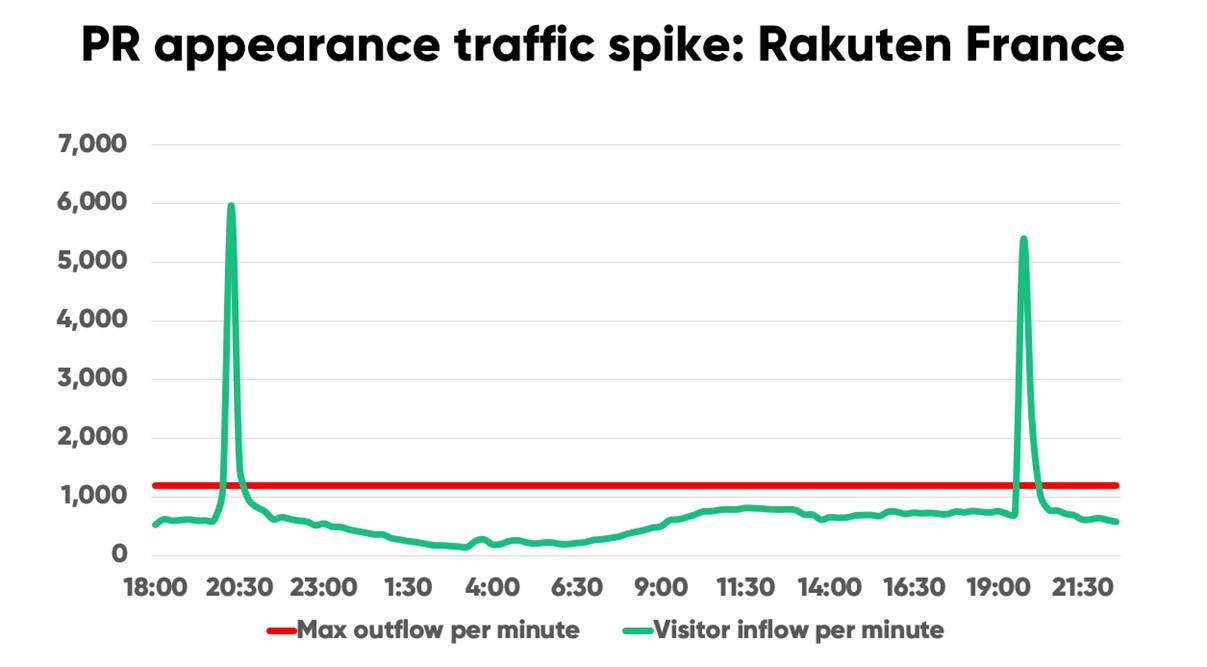
“It wasn’t even an ad or offer or anything like that. It just said who our spokesperson worked for and mentioned our brand, and immediately we saw a spike,” Thibaud Simond, Rakuten France’s Infrastructure manager told us. “We can’t have a reaction that takes even a minute. Fortunately, we were prepared with Queue-it.”
RELATED: A TV spot spiked Rakuten France’s traffic 819% in 2 minutes. Here’s how it went.
Black Friday isn’t just the biggest sales day of the year, it's also the biggest day for web traffic. Traffic on Black Friday in 2022 was on average 3x higher than a normal day.
Major sales days like Black Friday, Cyber Monday, and Singles’ Day, are known drivers of massive traffic for ecommerce sites. Reports show these days can see traffic 30 times higher than a normal day.
But even with planned days like these, where retailers know traffic peaks are coming, predicting the timing and magnitude of online traffic spikes is difficult to nail down.
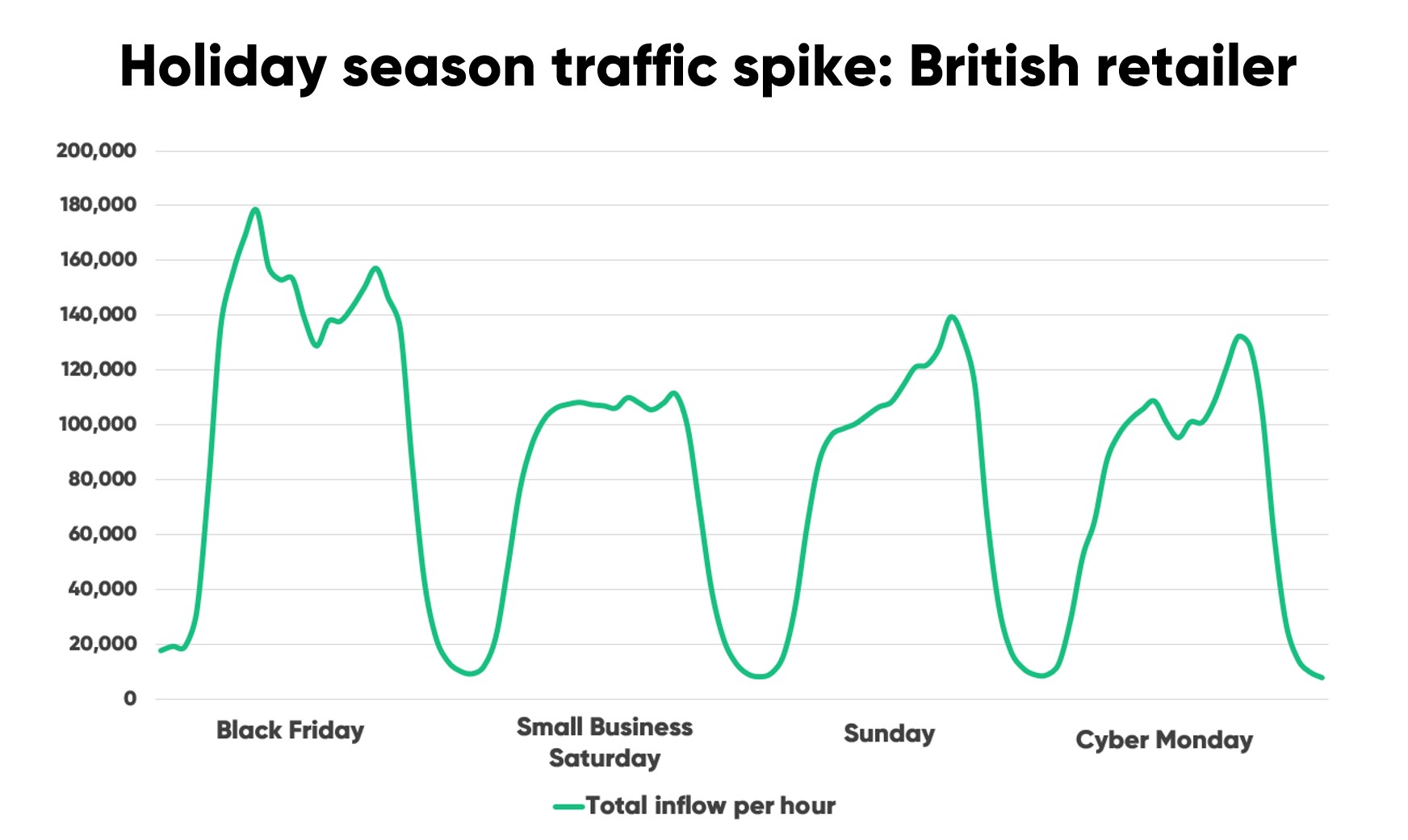
That’s why over 40 retailers crashed or slowed down because of high traffic during Cyber Five 2021. It’s why the major sale is among the most common causes of traffic-induced site crashes.
The chart below shows Cyber Five traffic data from an online retailer we work with. The spikes from 20,000 to almost 180,000 within just a few hours show why it's site crashes are so common during the Holiday Season.
Product releases are the third common cause of website crashes from high traffic. Common examples include the launch of a new product, sneaker drops, clothing brand collaborations, or limited-edition collectibles.
The hype around these product drops and launches often drive short, intense spikes in traffic.
These sudden spikes are some of the hardest for your site to deal with.
What’s more, product drops often see many visitors access your site early to try get a competitive advantage. These visitors refresh pages continually, and sometimes hit your site with bots. This can lead to a site crash before the sale even begins.
When cycling brand Rapha teamed up with one of the hottest names in streetwear for a product drop, they knew traffic would be massive.
In the first two hours of the drop, traffic spiked up and down dramatically. Traffic ranged from a couple hundred users per minute to almost 2,000 users per minute.
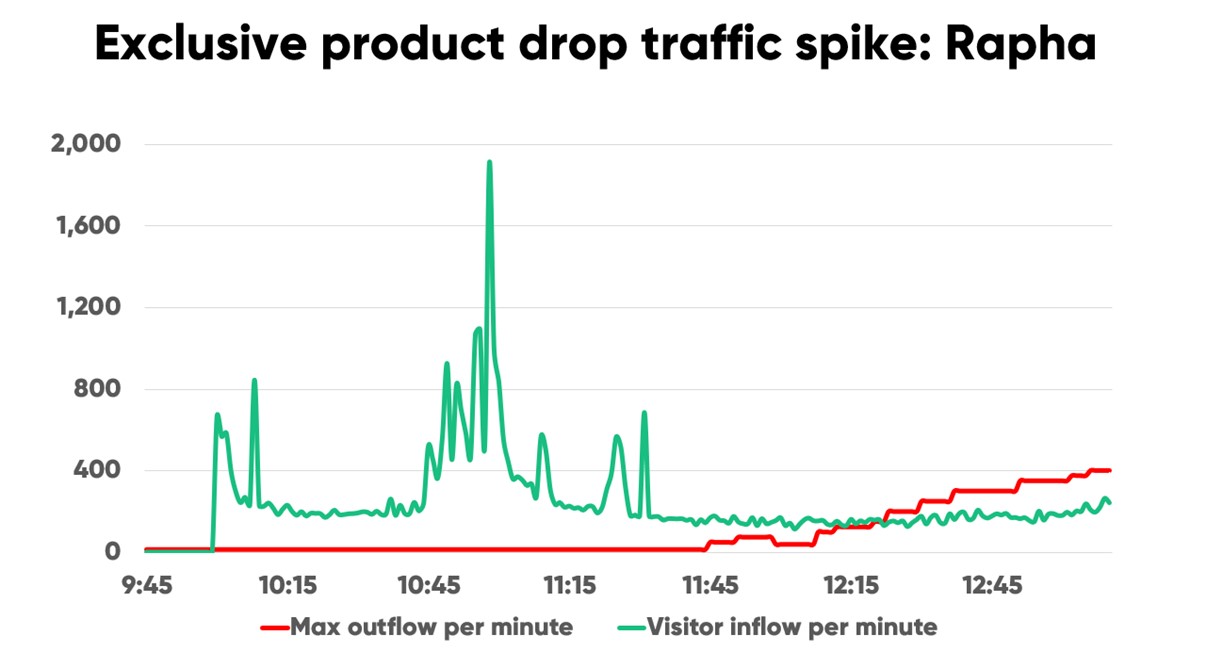
“Our partner only releases using this product drop method. Their whole technology stack is built around selling out—fast. In our first meeting, they disclosed they had seen 100,000 requests every few minutes,” said Rapha’s Engineering Manager Tristan Watson. “Unlike the partner, we work in a more traditional sales model, meaning our infrastructure isn’t designed to deal with the compressed traffic spikes you get during a ‘hyped’ drop.”
RELATED: How Rapha Used a Hyped Product Drop to Reward Loyal Members & Deliver Fairness
While website crashes are an everyday occurrence, 51% of IT experts consider them avoidable.
Here are a few ways to handle traffic to your website to prevent your website from crashing during high traffic.
Monitoring isn’t itself a solution to website overload. But the first step to preventing errors is understanding them. And without detailed monitoring, it’s not just your customers that get left in the dark.
A massive 74% of global IT teams rely on proactive monitoring to detect and mitigate outages. LogicMonitor found that IT teams with proactive monitoring endured the fewest outages of all those surveyed.
Proactive monitoring alerts you to failures in real-time and provide insights into your traffic levels and site performance.
But it isn’t just proactive monitoring that helps mitigate downtime. Insights into your application also means that after a crash you can conduct a root cause analysis based on facts, not guesswork. An accurate understanding of the root failure will allow you to optimize your system for the future.
Crash-proof your website with a virtual waiting room
Database requests and bottlenecks are often the Achilles’ heel of a website. A crucial part of your crash prevention strategy is strengthening and optimizing these weak points. Returning the supermarket analogy, this means adding a self-checkout option, or a “less than 12 items” lane, to keep things moving.
Essentially, you want to identify heavy database requests and limit their number, size, and complexity. There are many ways to build performance into your website. Some tactics include:
- Use a content distribution network (CDN), which responds to browser requests for your static content, like your home page and product images. This frees up your servers to focus on dynamic content, like your Add to Cart calls and checkout flows.
- Compress images and upload them at their intended display size. Use lazy loading to load media on demand, rather than all at once. Visitors perceive sites that load this way as faster, even if the actual load times are comparatively slow.
- Minimize the use of plugins where possible. They can quickly become out of date, and may not always maintain compatibility with your CMS or ecommerce platform.
RELATED: Optimize Your Website Performance with These 11 Expert Tips
Failing to prepare is preparing to fail. It may be a cliché, but it’s said for a reason: it’s true.
Most customers who come to Queue-it looking to prevent website crashes have no idea how many concurrent users their site can handle. Or, worse still, they believe their site’s capacity is far more than it actually is. This is one of the most common website capacity mistakes, and there’s a simple tool to understanding this that we point customers to: load testing.
Load testing is a kind of performance testing that involves sending increasing levels of traffic to your site under controlled conditions. The aim is to help you understand how it will perform when real visitors start to hit it in big numbers. Using open-source tools, it can be almost free to run.
RELATED: Everything You Need To Know About Load Testing
Load testing isn’t a one-and-done step, though. It’s a process.
Each test is likely to reveal new bottlenecks that need fixing. Adding or changing code also requires new load testing. And it’s easy to run load tests that miss key bottlenecks by failing to simulate true user behavior
LeMieux, one of our customers, load tested their site ahead of their big Black Friday sale. They determined their site capacity and used a virtual waiting room to control the flow of traffic and keep it below the threshold they’d determined.
But on the morning of their sale, they discovered slowdowns related to bottlenecks on their site search and filter features. The load testing of the site had not simulated true user behavior, focusing on volume of traffic and orders, rather than the resource-intensive dynamic search.
"We believed previous problems were caused by volume of people using the site. But it’s so important to understand how they interact with the site and therefore the amount of queries that go back to the servers."
Jodie Bratchell, Digital Platforms Administrator
This is a valuable lesson to keep in mind for your load tests. You need to understand how customers act on your site and ensure you replicate that behavior under load.
Fortunately for LeMieux, with Queue-it’s virtual waiting room in place they were able to lower the outflow of visitors from queue to website in real-time and quickly resolve the issue.
Also, be sure to notify your hosting provider that you’re running the load test. Otherwise, it could look like an unwanted DDoS attack. Many providers consider an unauthorized load test a violation of terms of service.
Few blogs will tell you to downgrade the user experience. But when you’re facing massive traffic, it’s an easy way to increase your capacity.
The issue with developments in website UX like dynamic search and personalized recommendations is they can be extremely performance intensive.
Well prepared ecommerce sites can toggle these non-critical features on and off. They might be a nice touch for customers 95% of the time, but when you’re facing 10x traffic spikes on Black Friday, it’s better to have a simple site than functions than an advanced site that crashes.
Try to identify performance intensive processes and either temporarily remove them for big days or scale them back.
For example, rather than an advanced, CPU-heavy search function, you can use a simpler search function to free up the database for business-critical purposes.
RELATED: The Worst Advice We’ve Heard to Prevent Website Overload
Autoscaling is critical for any business dealing with fluctuating traffic levels. It enables your servers to automatically adjust their computing power based on current load.
With autoscaling, your server capacity can temporarily expand and shrink according to your needs. This reduces the need to make predictions about traffic levels and makes your system more elastic and reactive.
Autoscaling saves money on the quiet days. And preserves performance on the big ones.
Or at least that’s the hope.
While this is what autoscaling does, it’s a bit more complicated than that. And as anyone who hosts a high traffic website knows, autoscaling isn’t the “cure-all” it sounds like.
There are three main reasons autoscaling is only a partial solution to traffic-induced crashes:
- Autoscaling is complex: It's extremely difficult and sometimes impossible to automatically scale all components of your tech stack. This means that even if you scale your servers, traffic still overloads bottlenecks like as databases, inventory management systems, third-party features like payment gateways, or performance-intensive features like dynamic search or a “recommended for you” panel.
- Autoscaling is reactive: Because traffic levels are hard to predict and autoscaling takes time to kick in, your systems likely won’t be ready in the critical moment they’re needed.
- Autoscaling is expensive: Most websites are built to perform under their usual amount of traffic. Building a website that can handle huge traffic peaks that only come a few times a year is like buying a house with 10 extra bedrooms and bathrooms because your family comes to visit sometimes—it’s expensive, impractical, and unnecessary.
RELATED: 3 Autoscaling Challenges & How to Overcome Them With Queue-it
For an in-depth look at what makes autoscaling so difficult, check out the video below or our blog on the challenges to successful autoscaling and how you can overcome them.
The shortcomings of autoscaling are less about the capacity of website servers, and more about the on-site behavior of customers. So when autoscaling isn’t enough, the solution is to manage and control the traffic.
“Autoscaling doesn’t always react fast enough to ensure we stay online. Plus, it’s very expensive to autoscale every time there’s high traffic. If we did this for every traffic spike, it would cost more than double what we pay for Queue-it. So Queue-it was just the better approach, both in terms of reliability and cost.”
MIJAIL PAZ, HEAD OF TECHNOLOGY
What do brick-and-mortar stores do when capacity is reached? How do venues deal with bottlenecks like ticket and ID checking? How do department stores deal with thousands of Black Friday customers trying to get into their store at once?
In all these scenarios, inflow is managed with a queue.
The same principle applies to ecommerce. You can prevent website overload by limiting the inflow of visitors to your site. And you can limit the inflow of site visitors with a virtual queue.
With a virtual queue (AKA a virtual waiting room) you can keep visitor levels where your site or app performs best. This ensures your overall capacity isn’t exceeded, but more importantly, it ensures the distribution of traffic to avoid overwhelming your bottlenecks.
A virtual waiting room manages and controls what autoscaling can’t: the customers.
"Nobody builds a website to handle hundreds of thousands of people just for a limited amount of time. Throughout the day it’s different, but having that major peak is insane. Queue-it is a great solution that saves the day and it works flawlessly."
ROBERT WILLIAMS, DIGITAL MANAGER
In high-demand situations, websites or apps with a waiting room redirect online visitors to a customizable waiting room using an HTTP 302 redirect. These visitors are then throttled back to your website or app in a controlled, first-come-first-served order.
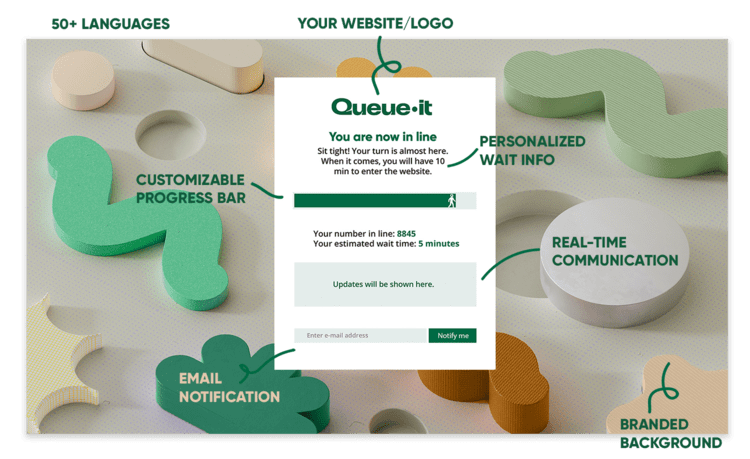
If you’re running a sale or registration that starts at a specific time, you can create a scheduled waiting room that holds early visitors on a countdown page and then randomize them just like a raffle, giving everyone an equal chance. Visitors arriving afterwards are added to the end of the queue on a first-in-first-out basis.
RELATED: Developers’ Guide to How Queue-it Works
You can control traffic flow down to the minute with a virtual waiting room. Set the traffic outflow from the waiting room to your site to exactly match what your load tests reveal you can handle—whether it’s a hundred, a thousand, or ten thousand users per minute.
And if unexpected bottlenecks appear in the system, you can reduce traffic flow on-the-fly.
High online traffic crashes sites by exceeding the capacity of its infrastructure. It’s often not just overall capacity, but the capacity of bottlenecks, that brings sites crashing down.
This means that while your overall capacity is important, to prevent website crashes you need to identify and optimize your site’s bottlenecks. Common bottlenecks include:
- Payment gateways
- Database calls
- Performance-intensive features
- Synchronous processes
These bottlenecks will typically work fine on a normal day. Like the supermarket that has 10 people entering each minute and can serve 10 people per minute, your bottlenecks should easily accommodate traffic under normal circumstances.
But there are three key scenarios that are anything but normal for traffic to ecommerce sites:
- The unexpected traffic spike
- The major sale
- The product drop/launch
These scenarios are the most common causes of website crashes in ecommerce, but apply to all public-facing industries.
Viral news stories, vaccination registrations, and tax returns crash public sector sites. Ticketing onsales and Instagram posts from pop stars crash ticketing sites. Class and course registrations crash education sites.
There are 6 key ways to stop websites from crashing due to high traffic:
- Embrace monitoring
- Optimize performance
- Load test your site
- Downgrade the user experience
- Configure autoscaling
- Manage traffic inflow
With these strategies, you not only increase your site capacity, but you also understand it better. Crucially, you understand the bottlenecks on your site that can’t scale and take control of the traffic before it hits those weak points.
While many people with cloud-based infrastructure introduce autoscaling, this doesn’t fix your bottlenecks, and often can’t adapt to scale fast enough, particularly when traffic predictions are low, or when traffic surges suddenly and unexpectedly.
That’s why many major online retailers choose to protect their site and run high demand events the same way stores facing too many customers always have—by controlling inflow with a queue.
(This blog has been updated since it was written in 2019)