3 autoscaling challenges & how to overcome them with a virtual waiting room


Autoscaling is an essential first step for any organization dealing with fluctuating levels of online demand. But autoscaling isn’t a comprehensive solution for crash prevention. Its shortcomings can crash your website and spike costs on your biggest days. Discover the three key challenges to successful autoscaling and how you can overcome them with a virtual waiting room.
Autoscaling is critical for any business dealing with fluctuating traffic levels. It enables your servers to automatically adjust their computing power based on current load.
With autoscaling, your server capacity can temporarily expand and shrink according to your needs. This reduces the need to make predictions about traffic levels and makes your system more elastic and reactive.
Autoscaling saves money on the quiet days and preserves performance on the big ones.
Or at least that’s the hope.
While this is what autoscaling does, it’s a bit more complicated than that. And as anyone who hosts a high traffic website knows, autoscaling isn’t the “cure-all” it sounds like.
Many of the companies that come to Queue-it looking to prevent website crashes already have autoscaling set up but continue to face issues when traffic surges.
Discover the three key shortcomings of autoscaling, hear concrete examples of why companies with autoscaling still suffer from site crashes, and learn how a virtual waiting room can protect your site in ways autoscaling can’t.
Table of contents
The main barrier to successful autoscaling is that scaling to handle large traffic requires scaling all essential components of your tech stack.
While scaling your servers on the cloud may be relatively easy, getting each distinct component of your tech stack to scale—either automatically or manually—is a difficult, expensive, and sometimes impossible task.
When Canadian Health Center NLCHI was facing massive traffic spikes, for example, they thought scaling their servers on AWS would help.
But as Andrew Roberts, the Director of Solution Development and Support told us, “this just brought the bottleneck from the frontend to the backend.”
This is all too common. As you scale, new bottlenecks almost always emerge.
These bottlenecks can come from dozens of potential places. Some of the most common one’s we’ve seen include:
- Payment gateways
- Database locks & queries (e.g. logins, updating inventory databases)
- Building cart objects (add to cart or checkout processes, tax calculation services, address autofill)
- Third-party service providers (authentication services, fraud services)
- Site plugins
- Synchronous transactions (e.g. updating inventory databases while processing orders and payments)
- Dynamic content (e.g., recommendation engines, dynamic search & filters)
"Not all components of a technical stack can scale automatically, sometimes the tech part of some components cannot react as fast as the traffic is coming. We have campaigns that start at a precise hour … and in less than 10 seconds, you have all the traffic coming at the same time. Driving this kind of autoscaling is not trivial."
ALEXANDRE BRANQUART, CIO/CTO
Unless your application is purpose-built for autoscaling, successfully setting up autoscaling for your entire infrastructure is extremely complex, time-consuming, and expensive.
Increasing capacity often starts off relatively cheap and easy. But as the number of concurrent users you want to handle goes up, so do costs.
Fixing a bottleneck early in the process might just be adjusting an algorithm or adding a bigger database server. But as your traffic gets larger, so do the challenges. You may need to re-architect systems, replace or change your data models, or even change core business logics and processes.
Plus, if bottlenecks come from third-party services such as payment providers, you may need to change providers or upgrade your subscription tiers.
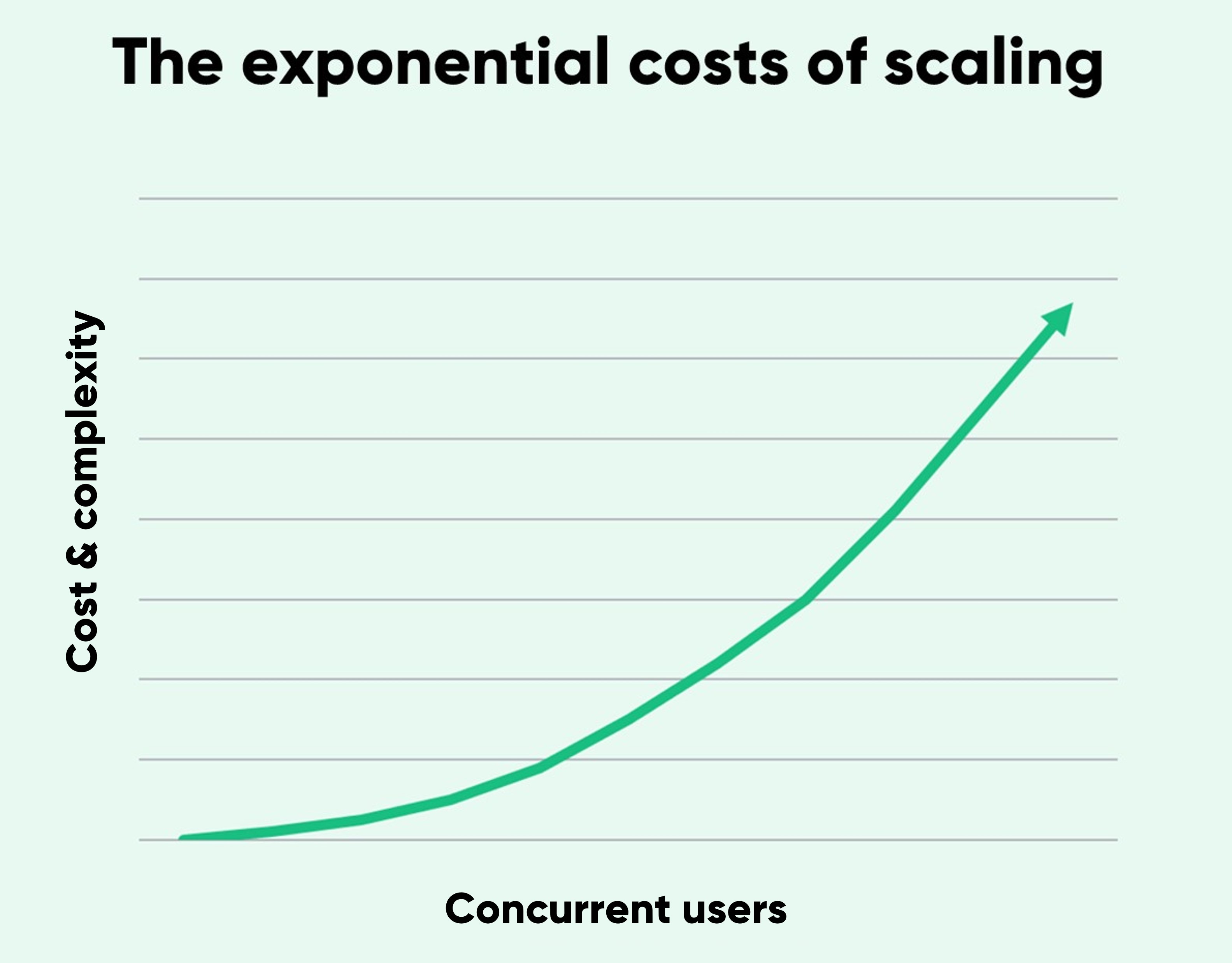
In this way, ensuring you can successfully autoscale (or even pre-scale) for peak demand is likely to become a huge project that drains time and money. And if your site only experiences occasional large traffic spikes—such as once a year on Black Friday or once a month when you drop a new product—this system overhaul and the costs that come with it are rarely worthwhile.
RELATED: Autoscaling Ecommerce Explained: Why Scaling Your Site is So Hard
Tristan Watson, the engineering manager at Rapha, describes the three main problems companies run into when scaling for a one-off event like a product drop:
“First, even if you run performance or capacity tests, it’s challenging to predict live customer behavior. You’ll always overprovision, which isn’t efficient.
"Second, a legacy application makes it near-impossible to scale all parts of the system to the same degree. You’re only as good as your least scalable system.
"Third, systems like inventory management require sequential steps like payment authorization that are often done by third parties, so there’s an inherent latency there that just can’t be shortened.”
The virtual waiting room is a bolt-on tool that lets your existing site perform like one that’s purpose-built for high traffic without re-architecting.
The solution addresses all three of the challenges to scaling Watson lists above:
- It removes the need to predict user behavior by automatically redirecting excess traffic off your infrastructure
- It lets you control the rate at which traffic hits your site, allowing you to tune traffic flow to match the max throughput of your least scalable system
- It can be configured to protect your entire site, specific pages, or just key bottlenecks like payment or login—meaning users who don’t take the protected action never see the waiting room
Virtual waiting rooms work by automatically redirecting visitors to an online queue that sits off your infrastructure when traffic exceeds the thresholds you’ve set. Visitors see a branded waiting room like the one below, with their number in line, their estimated wait time, and a progress bar. From here, they're flowed back to your site at the rate it can handle in a fair, controlled order.
RELATED: How Queue-it's Virtual Waiting Room Works [For Developers]
With Queue-it, you can keep your systems optimized for typical traffic levels and customer behavior, while still having the agility and confidence to embrace new trends and handle the unexpected.
“Queue-it’s a great bolt-on piece of infrastructure, completely dynamic to our needs. The virtual waiting room made much more sense than re-architecting our systems to try to deal with the insanity of product drops that take place a few times a year.”
TRISTAN WATSON, ENGINEERING MANAGER
Let’s say you overcome the challenge of getting your whole tech stack to scale automatically. The next essential question becomes: how quickly can it scale?
Autoscaling can’t reliably prevent load-induced crashes because it’s reactive, not proactive. It rarely responds quick enough to handle sudden spikes in traffic.
The reactivity of autoscaling is not a bug, it’s a feature. It’s what makes it automatic. Your autoscaling setup monitors key metrics and scales your infrastructure up or down accordingly, without you needing to do anything.
This reactive approach is useful during ordinary, day-to-day operations. But it creates a latency between traffic increasing and infrastructure scaling up or out, causing site failure when traffic spikes suddenly.
For many of the companies we work with, autoscaling falls short in scenarios like:
- Limited-edition product or sneaker drops
- Large flash sales (e.g. limited-time offers)
- Ticket onsales for a popular artist or festival
- High-profile public sector registrations
- Major influencer collaborations, PR pieces, or marketing campaigns
Take the following real-world traffic spike, for example. When online marketplace Rakuten appeared on the French national news, their site traffic spiked 819% in just two minutes.
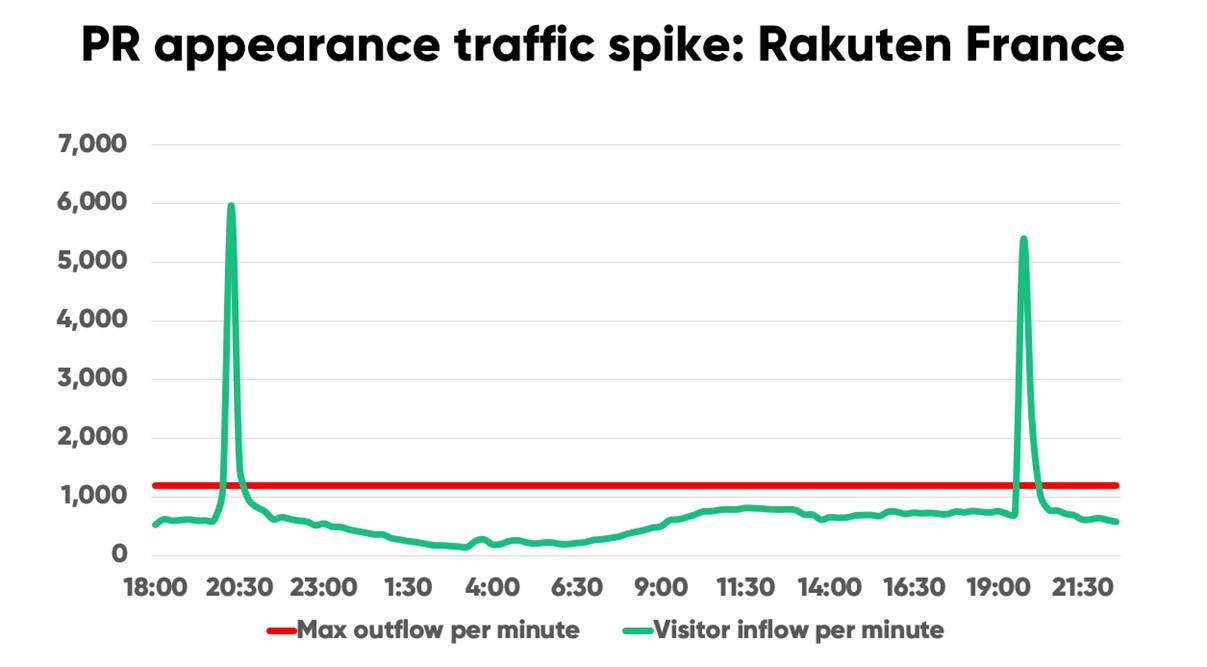
For large spikes like this, Rakuten France’s Infrastructure Manager Thibaud Simond says, “We can’t have a reaction that takes even a minute.”
So how fast can autoscaling react?
The short answer is: not fast enough.
The long answer is that how quickly a system can autoscale depends on both the level of traffic and the way autoscaling is set up.
Autoscaling is typically triggered by an aggregate of a metric you choose (e.g. CPU utilization or response time). These aggregates can be calculated by the minute but are usually gathered over larger timeframes.
For Azure services, for instance, the default aggregate period to trigger autoscaling is 45 minutes. Azure says it can be done quicker for web applications, “but periods of less than 25 minutes may cause unpredictable results.”
The “unpredictable results” of a more responsive approach to autoscaling include your infrastructure haphazardly scaling up and down, causing costs to spike and risking site reliability.
Plus, even if autoscaling could react in a minute (which is very rare), this only accounts for the time it takes to trigger autoscaling. Once autoscaling is triggered, the system still needs to actually scale (which takes time), then pass a readiness check (which takes more time) before it can start handling load.
The result of this is that traffic surges and crashes your web app. Then perhaps 10 minutes later your systems start scaling to handle the load—once the damage is already done.
“Our systems struggled with the traffic spikes. We first tried to handle these issues with autoscaling, but it rarely reacted fast enough to keep up with the sudden surge in users.”
ATSUMI MURAKAMI, CHIEF OF INNOVATION
But what about predictive autoscaling? That’s a proactive solution, can it handle sudden traffic spikes?
Unfortunately, no. In the types of scenarios listed above, predictive autoscaling is even more ineffectual than reactive autoscaling.
The reason for this is fairly simple: predictive autoscaling uses past behavior to predict future behavior. And user behavior during big brand moments and large-scale events is anything but predictable.
You can use predictive autoscaling to tune your capacity for consistent, day-to-day trends in user behavior, such as traffic increasing from 6 p.m. and decreasing after midnight.
But you can’t reliably forecast traffic spikes from a TV appearance, a product launch, or once-a-year Black Friday sales. Predictive autoscaling isn’t useful unless traffic is predictable.
With all this in mind, pre-scaling is typically the safest bet when preparing for a large spike in traffic. But pre-scaling has its own downsides, such as the high costs of overprovisioning and its inability to scale for unexpected peak demand.
"The amount of online traffic that we handle during Black Friday can be 15-20 times higher than on a normal day. Because the traffic increase is difficult to estimate, it makes it very difficult to plan the scale up of your infrastructure."
JOOST VAN DER VEER, CEO
After struggling to handle traffic spikes with autoscaling alone, all the companies quoted above decided to take control of their online traffic with a virtual waiting room.
Virtual waiting rooms protect your site and key bottlenecks from traffic spikes 24/7 so you can keep your site or app online and keep sales rolling in, no matter the demand.
Where autoscaling has a delayed reaction time, waiting rooms get triggered as soon as traffic surges. The solution monitors the flow of traffic to your site, then automatically activates when traffic exceeds the threshold you’ve set, sending excess visitors to the waiting room.
RELATED: Virtual Waiting Room Buyer’s Guide: How to Choose Your Online Queue System
Virtual waiting rooms don’t just react faster than autoscaling, they're also always ready to take traffic, meaning you don’t have to wait for it to scale to handle the load.
With the waiting room, you don’t need to predict at what time or in what volumes traffic will surge. So long as you know the max throughput of visitors your site can handle before facing issues, you can ensure visitor levels never exceed that threshold.
Plus, if you’re expecting a spike in traffic, you can proactively set up a waiting room to control visitor flow regardless of demand.
“Nobody builds a website to handle hundreds of thousands of people just for a limited amount of time. Throughout the day it’s different, but having that major peak is insane. Queue-it is a great solution that saves the day and it works flawlessly."
ROBERT WILLIAMS, DIGITAL MANAGER
Autoscaling is typically touted as a cost-saving solution. When Meta implemented autoscaling, for example, their average reported power savings were 10-15% per day.
But just as autoscaling loses its reliability when traffic spikes suddenly, so too does it lose its cost-saving potential.
If you’re dealing with sudden traffic spikes and unpredictable user behavior, there’s three key ways autoscaling can actually increase costs: overprovisioning, reducing reliability, and set-up and maintenance costs.
Keeping your site online during unpredictable, large-scale events by pre-scaling or autoscaling typically involves overprovisioning resources—driving huge costs.
Online traffic is difficult to predict and almost never arrives on your site in uniform patterns.
If 60,000 visitors visit your site in an hour, they don’t come at a rate of 1,000 per minute. They arrive in sharp, sudden spikes when the sale goes live, when your email hits customers’ inboxes, or when an influencer posts a link to the sale.
Traffic can go from 10,000 one minute, to 500 the next, then right back up to 10,000.
With both autoscaling and pre-scaling, you must keep your infrastructure scaled for peak demand for the duration of an event to keep it online—meaning you dramatically overprovision resources.
In this way, the pay-as-you-go model of autoscaling can quickly create runaway scaling costs when traffic spikes suddenly. You either crash because you haven’t scaled enough, or waste resources because you’ve scaled too much.
“Autoscaling doesn’t always react fast enough to ensure we stay online. Plus, it’s very expensive to autoscale every time there’s high traffic. If we did this for every traffic spike, it would cost more than double what we pay for Queue-it. So Queue-it was just the better approach, both in terms of reliability and cost.”
MIJAIL PAZ, HEAD OF TECHNOLOGY
If your site or app falls prey to any of the reliability shortcomings of autoscaling, they'll slow down or crash when you’re at your most visible.
This risks your bottom line, your customer loyalty, and your brand reputation:
- 91% of enterprises report downtime costs exceeding $300,000 per hour
- 60% of consumers are unlikely to return to a site if they encounter an error or issue
- 53% of global IT decision-makers think their company will experience an outage so severe it makes national media headlines
When your site fails due to an over-reliance on autoscaling, it can quickly create costs far larger than the amount you’re saving on cloud computing.
“We always pre-scale to a place where we know we’ll be able to handle the expected traffic. Then in case of anything unexpected, we have Queue-it on top that as a safety net. This gives us full confidence we won’t go down, but it also lets us give a quote guarantee to clients, because we know the system isn’t going to autoscale like crazy and cost a huge amount.”
MATT TREVETT, HEAD OF U.K.
Properly setting up autoscaling is a highly specialized and technically challenging process. You’ll need real DevOps experts, and a lot of their time.
To facilitate comprehensive autoscaling, you may need to re-architect systems or change core business procedures. To scale third-party services, you may need to increase your subscription level or change providers.
This isn’t a one-and-done process, either. You may need to repeat this process each time you embrace a new sale strategy, user behavior changes, or you add new components to your tech stack.
“I spoke to some enterprise engineers and they said ‘Sure, we can fix this [website problem] for you.’ But we’re talking about millions of dollars. That kind of money is just not in the budget for an organization like ours, especially to cover registrations that happen a few times a year.”
DAVE ARNOLD, IT MANAGER

A virtual waiting room keeps cloud computing costs under control by allowing you to scale to a fixed point (e.g. to handle 1,000 visitors per minute), then operate at maximum capacity without the risk of failure.
In a recent survey, Queue-it customers reported an average saving of 38% on server scaling costs and 33% on database scaling costs.
By controlling traffic inflow with a waiting room, you avoid the limitations of autoscaling and can more reliably keep your site online. In this way, Queue-it customers save money not just by spending less on scaling, but also by preventing lost revenue and resources caused by crashes when autoscaling falls short.
As a bolt-on, easy-to-use solution, setting up a virtual waiting room is far easier than preparing your website for large, unpredictable traffic spikes. Once you integrate Queue-it into your tech stack, you can set up a new waiting room within minutes.
Our customers report a 51% decrease in staff needed on-call for events, which enables increased productivity and frees up time to focus on delivering broader business value.
RELATED: Queue-it Customer Survey: Real Virtual Waiting Room Results From Real Customers
All this isn’t to say autoscaling is bad. It’s used by major companies across the globe—including ourselves—for good reason. And it’s one of our top recommendations to businesses struggling with fluctuating traffic.
But autoscaling is far from the “cure-all” it’s sometimes painted as. Scaling is hard, and like all solutions designed to make it easier, autoscaling has limitations.
It doesn’t address all bottlenecks, it’s reactive, it’s difficult and sometimes impossible to get right, and it can get quite expensive.
A virtual waiting room controls what autoscaling and other crash-prevention tactics can’t: the flow of online visitors.
It complements autoscaling, enabling you to protect your site against sudden spikes, safeguard key bottlenecks, and ensure scaling costs don’t get out of control. And as a bolt-on tool, the virtual waiting room doesn’t require you to re-architect systems for high-traffic events that only occur a few times a year.
Queue-it is the market-leading developer of virtual waiting room services, providing support to some of the world’s biggest retailers, governments, universities, airlines, banks, and ticketing companies.
Our virtual waiting room and the customers that use it are our core focus. We provide 24/7/365 support from across three global offices and have a 9.7/10 Quality of Support rating on G2 from over 100 reviews. Over the past 10 years, our 1,000+ customers have had over 110 billion visitors pass through our waiting rooms.
When Ticketmaster, The North Face, Zalando, Cathay Pacific, and The London School of Economics need to control their online traffic, they turn to Queue-it.
Book a demo today to discover how you can complement autoscaling with a solution that saves both your website and your bottom line.