The cost of downtime: IT outages, brownouts & your bottom line

Downtime affects organizations of all sizes across industries. But what's the average cost of downtime? How common is it? What's the difference in cost of downtime by industry? And how can you prevent it? Drawing on the latest downtime statistics, this article covers everything you need to know about the cost of downtime and how you can avoid paying it.
Downtime costs the top 2,000 companies $400 billion a year.
Meta's 2024 outage cost nearly $100 million in revenue.
A one-hour outage cost Amazon an estimated $34 million in sales.
A 20-minute crash during Singles' Day sales cost Alibaba billions.
The costs of downtime are often staggering. They affect everyone from small businesses to governments to retail giants. This article covers the latest downtime statistics, downtime costs by industry, and the steps you can take to prevent the nightmare that is IT and website downtime.
Table of contents
- What is IT downtime?
- How common is downtime?
- What's the cost of IT downtime?
- Where do downtime costs come from?
- Cost of downtime by industry
- How does website downtime impact retailers?
- The good news: Downtime is avoidable
- What causes server downtime?
- How to prevent downtime
- Cost of downtime infographic: The key statistics
Downtime occurs when a system can’t complete its primary function. It can be broken up into two types: IT outages and brownouts.
IT brownouts occur when a system is slowed or partially available. This might mean customers can access your site but certain services, like your search feature, don't function or load slowly.
With an IT outage, systems are completely unavailable. This means your site is completely crashed, along with related backend systems. In the case of Meta’s large IT outage, for example, not only were Meta’s flagship services (Facebook, WhatsApp, Instagram) down, but so too were their internal systems—employees couldn’t even get into offices using their keycards.
Some IT downtime is planned for system maintenance. But most downtime is unplanned, and occurs due to high traffic, system failures, or malicious attacks.
RELATED: How High Online Traffic Can Crash Your Site
Now you understand downtime, let’s look at how much of an issue it really is. IT outages and brownouts are more common than you’d think.
LogicMonitor’s survey of enterprise-level IT leaders found that over the past three years:
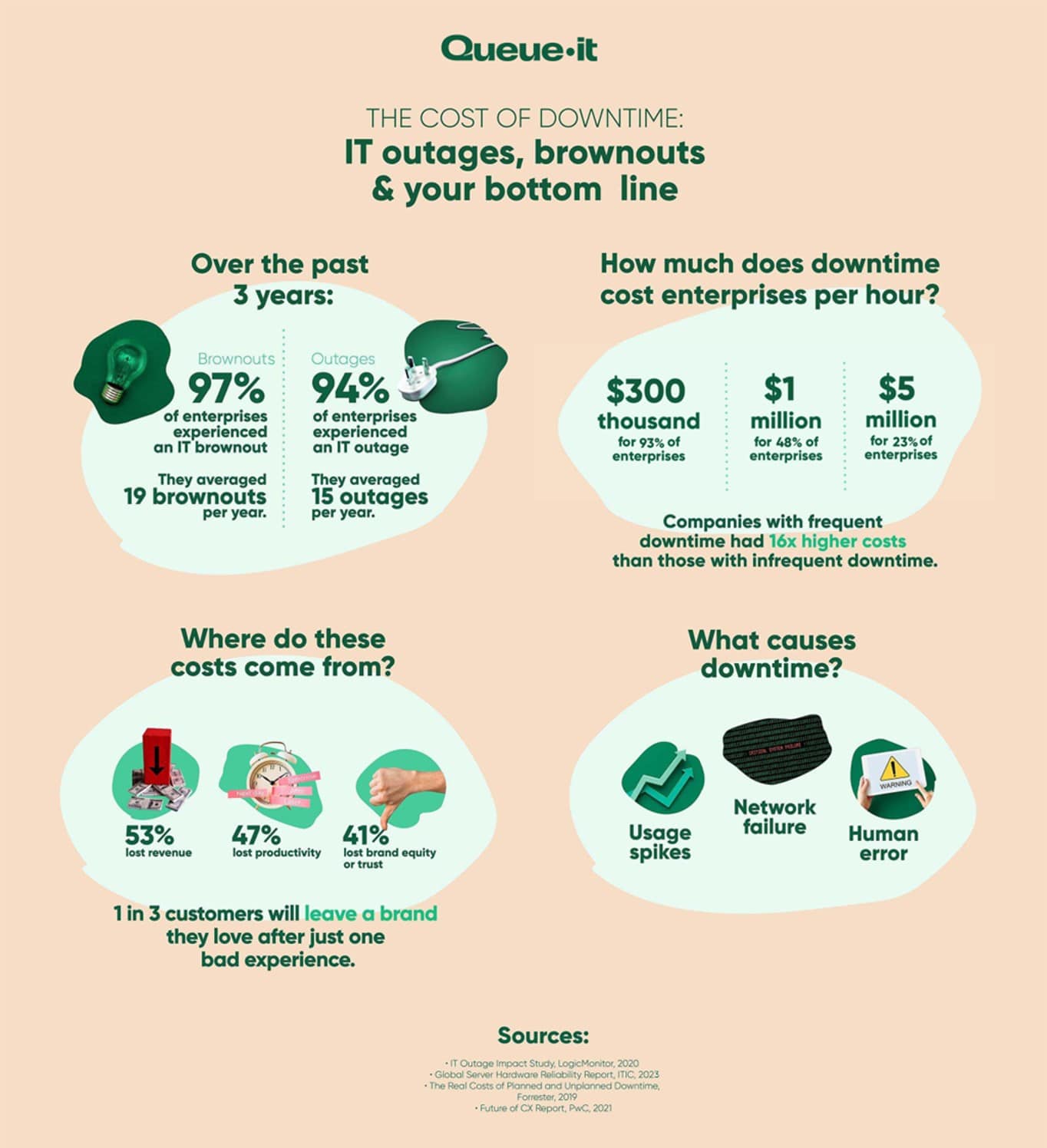
- 97% of enterprises experienced an IT brownout
- 94% of enterprises experienced an IT outage
- The average amount of brownouts for enterprises was 19 per year
- For IT outages, that number was 15
According to a report from Acronis, 76% of companies suffered downtime in 2022. Among the Global 2,000 (the top 2,000 companies worldwide), the typical company sees 466 hours of cybersecurity-related downtime and 456 hours of application or infrastructure-related downtime.

Whether downtime is increasing or not is up for debate.
In LogicMonitor's survey of IT leaders, 51% leaders said downtime has increased since March 2020.
But Uptime Institute reports a decline in outages per site, from 78% in 2020, to 60% in 2022.
But the costs and duration of downtime are increasing:
- The proportion of outages that took over 48 hours to fully recover from has increased from 4% in 2017 to 16% in 2022
- The proportion of single incidents costing over $100,000 has increased from 39% in 2019 to 70% in 2023
- Organizations of all sizes, spanning all verticals, reported an uptick in their firm’s hourly downtime costs in 2023 compared to 2022
ITIC predict the costs of downtime will continue to grow as organizations rely more on the internet for business-critical processes.
It's clear downtime is no rare occurrence. And as internet use continues to grow, the world’s IT leaders are convinced it’ll become more common still.
But if IT downtime is so common, how bad can it really be? What’s the cost of downtime?
Every number you can find on downtime tells one simple story: avoid it at all costs. For enterprises, the average cost of downtime is staggering. And the effects go far beyond revenue lost while servers are down:
- Costs are up to 16x higher for companies that have frequent outages and brownouts compared with companies who have fewer instances of downtime
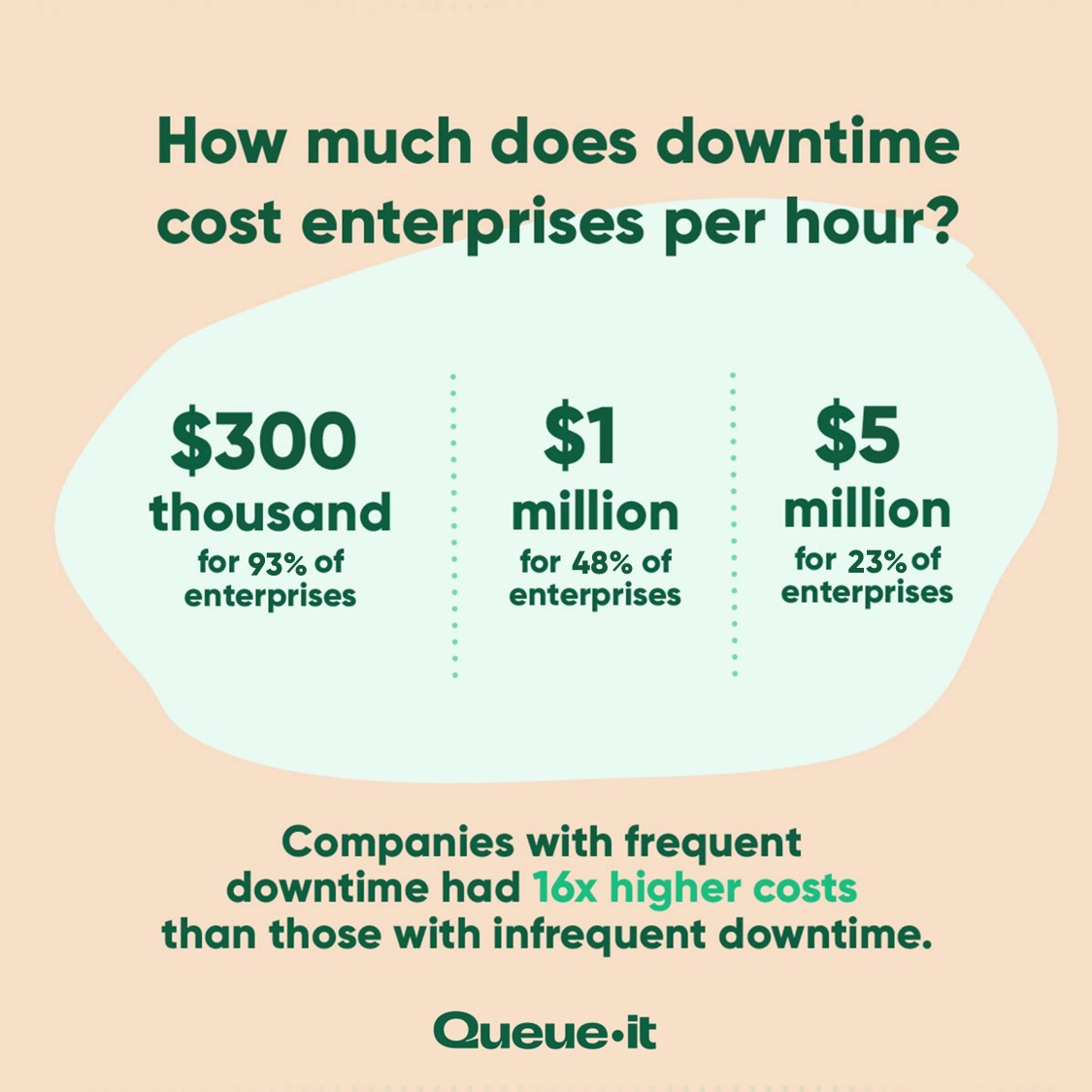
- 93% of enterprises report downtime costs exceeding $300,000 per hour
- For 48% enterprises, hourly costs exceed $1 million per hour
- And for 23% of enterprises, downtime costs exceed $5 million per hour
- Among the top 2,000 companies, the average cost of downtime is $200 million per company per year (or 9% of profits)
Even among non-enterprises, downtime costs are exceedingly high:
- 57% of small-to-medium sized businesses (SMBs) with 20 to 100 employees said downtime costs them $100,000 per hour
- Another report found that for SMBs, the average cost of dowtime is $8,000-$25,000 per hour
These numbers match up with what Jamie Rau, Marketing Director for SMB Micro Kickboard told us:
"We estimate a loss of $15,000 occurred on a key spring campaign day, based on approximately 30 percent of shoppers not being able to place orders due to website failure. The website couldn't handle the customer inflow. We realized we needed something else in place to protect our customers' online shopping experience and the company's overall revenue."
The cruel irony of traffic-induced downtime like Micro Kickboard's is that it often occurs on your biggest days—when you’re launching your new product, running a flash sale, or releasing tickets for a major artist. This means your downtime costs often aren't just based on your average hourly revenue, they're based on your peak hourly revenue.
"Downtime of even one to two seconds can be very costly. When you multiply that by 60,000-100,000 people, that adds up. Whenever anyone else is involved as well, influencers or another brand, we don't want to affect how their audiences view them."
ALEX WAKIM, DIRECTOR OF OPERATIONS & BUSINESS DEVELOPMENT
Get peace of mind on your busiest days with your free guide to managing ecommerce traffic peaks

Downtime costs come from a wide variety of sources, ranging from lost revenue, to additional infrastructure capacity, to brand campaigns designed to restore trust.
Forrester’s survey of IT directors in large US enterprises reveals the most common drivers. When asked where the cost of downtime comes from:
- 53% said lost revenue
- 47% said lost productivity
- 41% said lost brand equity or trust
RELATED: How To Ensure Website Performance When You Increase Ecommerce Traffic

This tracks with IDC's survey of enterprise CIOs and IT managers, who said the top three impacts of downtime were:
- End-user satisfaction and customer experience
- Financial penalties and regulatory compliance
- Employee satisfaction and ability to work effectively
In Queue-it's Age of Online Trust Survey, consumers revealed the impact of downtime on trust in online businesses:
- 74% of consumers say a reliable website or app is key to driving their trust
- 64% of consumers are less likely to trust a business after experiencing a website crash
- 66% are less likely to trust a business after experiencing overselling
- 87% of consumers prefer a short wait for a website that works than immediate access to a slow or buggy website
- 84% prefer an online queue to a crashed website or error page
Splunk's survey of executives at the global gives a more detailed breakdown of direct downtime costs. Downtime cost the average company they surveyed $200 million per year. That $200 million is made up of:
- Lost revenue: $49M (24.5% of costs)
- Regulatory fines: $22M (11% of costs)
- SLA penalties: $16M (8% of costs)
- Settlement/legal costs: $15M (7.5% of costs)
- Brand trust campaigns: $14M (7% of costs)
- PR/investor relations: $13M (6.5% of costs)
- Lost productivity: $12M (6% of costs)
- Ransomware payouts: $11M (5.5% of costs)
- Additional infrastructure capacity: $11M (5.5% of costs)
- Overtime wages: $11M (5.5% of costs)
- Cyber insurance premiums: $10M (5% of costs)
- Recovering from backups: $9M (4.5% of costs)
- Extortion payouts: $8M (4% of costs)
The survey also revealed that downtime has a range of indirect costs related to reputation, partnerships, and internal resources:
- 28% say downtime diminishes shareholder value
- 44% say downtime has damaged their brand reputation
- 65% say downtime has generated national or internation news
LogicMonitor's survey of global IT decision makers revealed similar concerns among IT professionals, finding:
- 53% think their company will experience a brownout or outage so severe that it makes national media headlines
- The same percentage (53%) think their company will experience a brownout or outage so severe that someone loses their job as a result
- 31% say they have experienced brand/reputation damage due to IT brownouts, while 32% say they have experienced brand/reputation damage due to IT outages
- 30% said brownouts and outages lowered their stock price
It's no wonder 54% of businesses say they can't calculate their hourly downtime costs.
When Meta suffered their outage, its stock plummeted 5%. And while few will pity Mark Zuckerberg, this fall represented a $6 billion hit to his net worth in a day. That’s more than the average lifetime earnings of over 2,000 Americans—lost by one man in one day.
With those kind of numbers, you can see why Zuckerberg got so angry about the prospect of a crash in The Social Network.
But Zuckerberg and Meta should consider themselves lucky. 16% of IT leaders say their organization was shut down permanently because of IT outages over the past three years.
RELATED: How To Prevent Website Crashes in 10 Simple Steps
Downtime costs vary widely across industries for the Global 2,000. Costs are lowest in the communications and media industry, at $143 million per year—28.5% below the average across industries. The cost of downtime is highest in the retail industry, with annual costs among the Global 2,000 averaging $287 million—43.5% higher than the average.
The main cost drivers during downtime are also diverse. The average public sector org, for instance, spends $73 million annually on damage control due to downtime, compared to just $17 million in the financial services industry.
Here's a breakdown of the average cost of downtime by industry and the key drivers of downtime within each one:
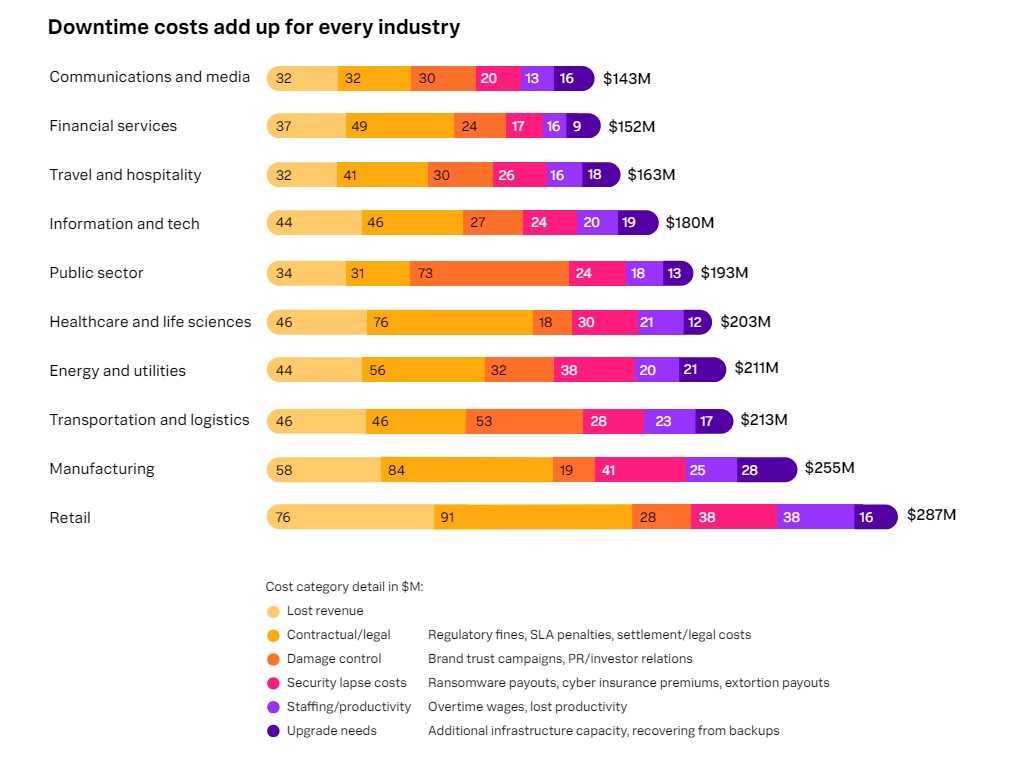
The costs of downtime are highest in the retail industry due to higher levels of lost revenue, larger contractual/legal expenses, and a bigger impact on staffing/productivity than in any other industry.
But retailers also suffer more from downtime because competition is fierce and customers are fickle. These impacts are clear in Splunk’s survey of the top 2,000 companies, with:
- 40% saying downtime impacts average customer lifetime value
- 29% saying they’ve lost customers to downtime
- 40% saying downtime damages reseller and/or partner relationships
In their Future of CX report, PwC surveyed 15,000 consumers and found that 1 in 3 customers will leave a brand they love after just one bad experience, while 59% would completely abandon a company after two or three negative interactions. These findings are mirrored in a Fullstory survey which found:
- 77% of consumers leave a site without buying if they encounter an error
- 60% are unlikely to return to a site later if they encounter an error
- 65% trust a business less when they experience a problem
To make things worse, retail site crashes are most likely to occur when you’re at your most visible—think Black Friday sales, product drops, successful marketing and PR campaigns. This is because high traffic and sudden usage spikes are among the most common causes of downtime.
In a recent survey, 46% of Brits said they’d ditch retailers altogether if their apps crashed on Black Friday. It's no wonder 70% of retail marketers reported concerns about downtime during the holiday season.
RELATED: How to Avoid the Website Capacity Mistake Everyone Makes
“Website crashes and slowdowns were leading to lost sales opportunities and the added costs of getting the site back online. We were also afraid that it would eventually result in losing trust from our customers and collaborators.”
JUNJI HAYASHI, CEO, MAXIM CO.
Let’s put some of these downtime statistics into concrete terms for an enterprise-level retail site.
Say you’re a large retail site running a Black Friday sale. You have 1,000 visitors per minute, an average order value of $20, and a 5% conversion rate. This would give you an hourly visitor count of 60,000, and hourly sales of $60,000 during the sale. To keep things simple, let’s say your site crashes for exactly one hour. That means:
- $60,000 in lost revenue
- 36,000 customers (60%) who are unlikely to return to your site
- 20,000 customers (33%) who won’t return to your site
- 39,000 customers (65%) who have less trust in your business than before
And these numbers only account for the customers who visited your site while it was down. They don’t include impacts to productivity, negative reviews, and the potential for a stock price impact. They don’t include the impacts of headlines like this:
IT outages and brownouts are terrible for business. And while the bad news is they’re common and on the rise, there’s good news too:
78% of experts consider downtime to be avoidable.
What would avoiding downtime look like for your business? Forrester asked IT directors what benefits they would expect for their organization if it had no downtime:
- 63% said increased revenue
- 53% said reduced operational cost
- 51% said improved competitive advantage
- 50% said improved employee productivity
You’d be hard-pressed to find a change to a business that would have an impact as substantial as eradicating downtime.
It's no wonder the overwhelming majority of CFOs for the Global 2,000 say protecting against all types of downtime is either “important” or “very important” in corporate funding strategy.
So in the second half of this article, we’ll dive into exactly that: how you can avoid outages and brownouts. But first, we need to understand what’s causing them.
There are 6 main reasons websites and servers crash or experience slowdowns:
|
Error |
Example |
|---|---|
|
1. Code errors |
A typo at Amazon took a backbone of the internet offline in 2017. |
|
2. Domain name system (DNS) provider failures |
A DDoS attack aimed at DNS provider Dyn cut off dozens of top websites in 2016. |
|
3. Web hosting provider issues |
Danish construction workers dug up a fiber cable to a server center on Black Friday 2018, causing over 2,000 websites to go dark. |
|
4. Malicious attacks |
In 2022, over 70 Ukrainian government websites crashed after an onslaught of cyber attacks. |
|
5. Expired domain name |
The Dallas Cowboys forgot to renew their domain name, causing their website to crash on the same day they fired their head coach in 2010. |
|
6. Website traffic surges |
Coinbase’s 2022 Super Bowl ad had a QR code linking to its website. The massive influx of traffic from the ad brought their service crashing down. |
LogicMonitor’s survey of enterprise-level IT leaders found that the most common of these downtime causes were:
- Network failure (web hosting provider issues)
- Usage spikes (website traffic surges)
- Human error (code errors or expired domain names)
RELATED: The 8 Reasons Why Websites Crash & 20+ Site Crash Examples
There are several tools and tactics you can implement to dramatically reduce the risk of unplanned downtime. Just about every big company with an online presence leverages some combination of these tools to boost their reliability.
The following video runs through 6 steps you can take today prevent your website from going down. For more detailed info, continue reading through the points below.
1. Embrace monitoring
Monitoring isn’t itself a solution to website crashes. But the first step to preventing errors is understanding them. And without detailed monitoring, it’s not just your customers that get left in the dark.
If you don’t have insights into your application’s metrics, you’re inviting issues you’ll never understand. Monitoring helps alert you to failures and provides more detailed insight into uptime and traffic.
A massive 74% of global IT teams rely on proactive monitoring to detect and mitigate outages. And among the IT professionals surveyed by LogicMonitor, those with proactive monitoring had the fewest number of outages and brownouts.
It’s not just proactive monitoring that helps mitigate downtime. Detailed monitoring means that after downtime occurs, you can conduct a root cause analysis based on facts, not guesswork. An accurate understanding of the root failure will allow you to optimize your system for the future.
If your application is a black box, there’s good news: There are a slew of log management and application performance management (APM) SaaS solutions that can help you and which are easy to get up and running (Datadog, New Relic, Loggly, and Splunk just to name a few).
2. Load test your website
Most customers who come to Queue-it looking to prevent website crashes have no idea how many concurrent users their site can handle. Or, worse still, they believe their site’s capacity is far more than it actually is. This is one of the most common website capacity mistakes, and there’s a simple tool to understanding this that we point customers to: load testing.
Load testing is a process which tests the performance of a site, software, or app under a specified load. This helps organizations determine how their service behaves when accessed by large numbers of users.
With load testing, organizations can discover how much traffic their site can handle before bugs, errors, and crashes become an issue. They can also identify bottlenecks in their systems to understand their vulnerabilities.
The good news is load testing has become cheaper and easier in recent years, thanks to open source tools like Apache JMeter and Gatling when run in the cloud using a service like RedLine13.
The bad news is it’s often difficult to simulate true user behavior with load testing, and even for sites that run load tests, some common bottlenecks are easily missed.
RELATED: Everything You Need To Know About Load Testing
This happened to equestrian brand LeMieux, who load tested their site before running their hugely popular Black Friday sales. They identified the capacity of the site and implemented a virtual waiting room to ensure the outflow of customers to the site was below the capacity their load-tests revealed.
The issue was, when the sale went live, there were slowdowns caused by customers using the site search and filter features. The load tests didn’t run scripts that tested these server-intensive features, resulting in slowdowns on the site.
"We believed previous problems were caused by volume of people using the site. But it’s so important to understand how they interact with the site and therefore the amount of queries that go back to the servers."
Jodie Bratchell, Ecommerce & Digital Platforms Administrator at LeMieux
With Queue-it in place, they took control over the customer flow by lowering the outflow of visitors from waiting room to website in real-time. The rest of the day was a resounding success. The limited-release products sold out and customer complaints disappeared completely.
3. Configure autoscaling
Autoscaling is critical for any business dealing with fluctuating traffic levels. It enables your servers to automatically adjust their computing power based on current load.
With autoscaling, your server capacity can temporarily expand and shrink according to your needs. This reduces the need to make predictions about traffic levels and makes your system more elastic and reactive.
Autoscaling saves money on the quiet days. And preserves performance on the big ones.
Or at least that’s the hope.
While this is what autoscaling does, it’s a bit more complicated than that. And as anyone who hosts a high traffic website knows, autoscaling isn’t the “cure-all” it sounds like.
There are three main reasons autoscaling is only a partial solution to traffic-induced crashes:
- Autoscaling is complex: It's extremely difficult and sometimes impossible to automatically scale all components of your tech stack. This means that even if you scale your servers, traffic still overloads bottlenecks like as databases, inventory management systems, third-party features like payment gateways, or performance-intensive features like dynamic search or a “recommended for you” panel.
- Autoscaling is reactive: Because traffic levels are hard to predict and autoscaling takes time to kick in, your systems likely won’t be ready in the critical moment they’re needed.
- Autoscaling is expensive: Most websites are built to perform under their usual amount of traffic. Building a website that can handle huge traffic peaks that only come a few times a year is like buying a house with 10 extra bedrooms and bathrooms because your family comes to visit sometimes—it’s expensive, impractical, and unnecessary.
RELATED: 3 Autoscaling Challenges & How to Overcome Them With Queue-it
The shortcomings of autoscaling are less about the capacity of website servers, and more about the on-site behavior of customers. So when autoscaling isn’t enough, the solution is to manage and control the traffic.
“Autoscaling doesn’t always react fast enough to ensure we stay online. Plus, it’s very expensive to autoscale every time there’s high traffic. If we did this for every traffic spike, it would cost more than double what we pay for Queue-it. So Queue-it was just the better approach, both in terms of reliability and cost.”
MIJAIL PAZ, HEAD OF TECHNOLOGY
4. Manage traffic inflow
What do brick-and-mortar stores do when capacity is reached? How do venues deal with bottlenecks like ticket and ID checking? How do department stores deal with thousands of Black Friday customers trying to get into their store at once?
In all these scenarios, inflow is managed with a queue.
The same principle applies to digital platforms. You can prevent website overload by limiting the inflow of visitors to your site. And you can limit the inflow of site visitors with a virtual queue.
With a virtual queue (AKA a virtual waiting room) you can keep visitor levels where your site or app performs best. This ensures your overall capacity isn’t exceeded, but more importantly, it ensures the distribution of traffic to avoid overwhelming your bottlenecks.
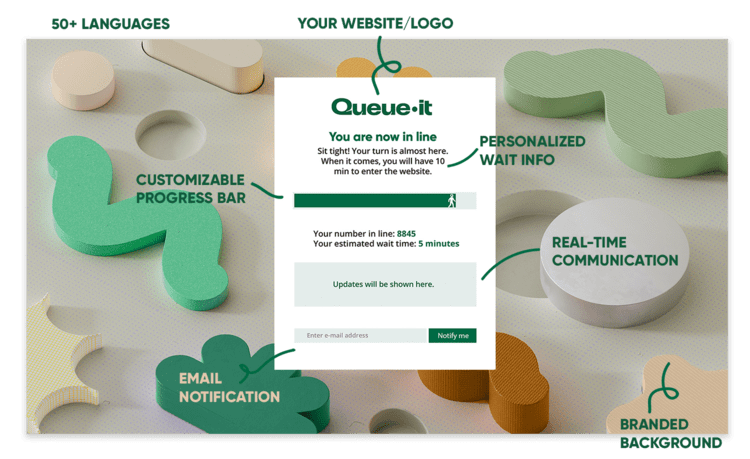
A virtual waiting room is a cloud-based solution for websites and applications to manage surges in online traffic. When traffic exceeds an organization’s site or app capacity, visitors are redirected to a waiting room using a standard HTTP 302 redirect. They're placed in a customizable waiting room, given transparent wait information, then redirected back to the site or app in a first-come, first-served order.
Virtual waiting rooms let you manage and control what autoscaling can’t: the customers.
"Nobody builds a website to handle hundreds of thousands of people just for a limited amount of time. Throughout the day it’s different, but having that major peak is insane. Queue-it is a great solution that saves the day and it works flawlessly."
ROBERT WILLIAMS, DIGITAL MANAGER
Alongside keeping your site online no matter the demand, Queue-it customers report that the virtual waiting room:
- Improves customer experience
- 88% say their customers’ online experience has improved
- 71% saw fewer customer complaints for sales/registrations
- 81% say their sales are fairer with Queue-it
- 50% say their insight into genuine & malicious traffic has improved
- Saves them scaling costs
- On average customers report a 38% decrease in server scaling costs
- On average customers report a 33% decrease in database scaling costs
- Increases productivity & efficiency
- 81% say running sales/registrations is less stressful
- 51% average reduction in staff needed on-call during sales/registrations
- 81% sell through product more efficiently
RELATED: The Comprehensive Guide to Virtual Waiting Rooms: All Your Questions Answered
5. Block bad traffic & bots
The above steps are important to handle traffic as it reaches your site. But there’s also traffic you’ll want to keep off your site altogether. This unwanted traffic often comes in the form of bad bots or attacks on your servers. Keeping them off your infrastructure is essential to mitigating downtime.
Bots make up nearly two-thirds of internet traffic. And while there are good bots like the Google bots that help your site appear in search results, there are also bad bots looking to abuse your systems. These bad bots are responsible for a staggering 39% of all internet traffic.
And during sales like limited-edition product drops and Black Friday or Cyber Monday sales, this number is much higher.
- 45% of online businesses said bot attacks resulted in more website and IT crashes in 2022
- 33% of online businesses said bot attacks resulted in increased infrastructure costs
- 32% of online businesses said bots increase operational and logistical bottlenecks
While most businesses are concerned about high traffic caused by real users, many are unaware of the real risks that come from bot, DDoS, and data center traffic.
Queue-it offers several tools to block bad bots and malicious traffic before it hits your site. These include data center IP blocking, proof of work and CAPTCHA challenges, challenging of suspicious traffic, and an invite-only waiting room letting only the users you choose get access to your site.
With these tools, dozens of Queue-it customers have blocked millions of bots and bad actors from their high-demand events. These include:
- A top U.S. ticketing company, which blocked 3.2 million bots during one ticket onsale
- A Japanese gaming company, which blocked 225,000 bots during a hyped product drop
- A U.S. sneaker retailer, which cut their traffic during sneaker drops in half with the help of Queue-it
RELATED: Block Sophisticated Bots With Multi-layered Bot Protection
Don’t pay the cost of downtime
It’s safe to say downtime is prohibitively expensive. It’s an avoid at all costs problem many large organizations remain vulnerable to.
While downtime may be increasing, so too is our capacity to understand and mitigate it.
Queue-it specializes in keeping websites and applications online no matter the demand, having served over 75 billion users across 172 countries. Virtual waiting rooms give organizations control over their web traffic to deliver a fair and seamless user experience to visitors.
With advanced monitoring features, robust tools to block bots and abuse, and superior protection against usage spikes, a virtual waiting room equips organizations avoid the costs of downtime. It empowers them to get back to doing what they do best—delivering high-quality goods and services to their visitors and employees.
Queue-it empowers the world’s biggest businesses to perform on their busiest days. When Ticketmaster, The North Face, and Rakuten need to manage high-demand events, they turn to Queue-it.
(This blog has been updated since it was written in 2022).