Spike testing: Everything you need to know to safeguard your site

Product drops. Flash sales. Concert ticket sales. High-visibility events can send massive web traffic spikes to your site in an instant, causing it to come crashing down. Spike testing lets you prepare for these events—and reveals what you need to do to optimize performance. Discover everything you need to know about spike testing, including what it is, why it’s important, spike testing examples, and what to do when a spike test fails.
Table of contents
- What is spike testing?
- Why are spike tests important?
- Spike testing in performance testing
- Web traffic spike examples that show the importance of spike testing
- Spike tests & autoscaling
- Spike testing best practices
- How to do a spike test
- How to handle web traffic spikes
- Summary: Spike test to impress
Spike testing is a type of performance testing that involves flooding a site or application with sudden and extreme increases and decreases (spikes) in load. It’s used to determine how quickly a system can scale, how fast it can recover, and whether traffic spikes produce bottlenecks or performance issues.
Spike testing is similar to load testing. But unlike load testing, spike testing doesn’t involve applying a uniform or expected load to your system (e.g.,100 requests per minute for 20 minutes). Instead, your spike test might simulate 1,000 requests one minute, then 100 the next, then 2,000 the next, and so on.
Testing performance in this way simulates situations where traffic is large, unpredictable, and sudden. It helps businesses and organizations prepare for events like:
- A limited-edition product or sneaker drop.
- A large flash sale (e.g., Black Friday or Cyber Monday).
- A ticket onsale for a popular artist or festival.
- A high-profile public sector registration.
- A major influencer collaboration, PR piece, or marketing campaign.
If you’re running any of these activities, or are expecting large fluctuations in traffic, spike tests reveal how your site or app will handle the traffic. They give you the insights you need to avoid crashes and deliver the fast, error-free experience your customers deserve.
Spike tests are important because in many real-world scenarios traffic doesn’t arrive in a steady, consistent pattern. Spike tests simulate traffic spikes in a test environment to show how they affect your performance, whether they expose bottlenecks or issues with scalability, and how well your system recovers.
Usage spikes are the second most common cause of downtime (after network failure). Even major companies with highly scalable systems and autoscaling configured suffer from crashes and slowdowns caused by high traffic.
Traffic from a Super Bowl ad crashed Coinbase’s site. Prime Day deals crashed Amazon’s site. The rush to file tax returns crashed the I.R.S. site.
RELATED: How High Online Traffic Can Crash Your Website
If you’re a company that runs high-traffic sales or registrations or experiences sudden climbs and falls in traffic, spike checks are essential to ensuring your system can handle the spikes without crashing, slowing down, or producing errors.
Failing to prepare is preparing to fail. And crashes and outages pose major threats to:
- Your bottom line: 91% of enterprises report downtime costs exceeding $300,000 per hour.
- Your customer loyalty: 1 in 3 customers will leave a brand they love after one bad experience.
- Your brand reputation: 32% of IT professionals say their brand reputation was damaged by outages.
- Your job: 53% of IT professionals say their company will experience an outage so bad someone loses their job.
Spike testing is not only about determining how the system performs during the spike but also how it recovers in the time between spikes. If downtime costs you $300,000 per hour, it’s costing around $5,000 per minute—so you want recovery time to be as fast as possible.
Even if your site or app doesn’t crash, most systems need some time to stabilize after a large spike in traffic. If you suddenly decrease load and discover there are still errors, response times remain high, or worse, the system never recovers, the spike test has revealed a major issue.
Spike test meaning & why it matters summary: Spike tests flood your system with sudden, extreme increases and decreases in load a test environment to see how your system performs and show you how to prevent crashes, slowdowns, and errors during high-traffic events. Spike testing is important for protecting your site against surges in usage, which is the 2nd most common cause of website crashes.
Spike testing is a type of performance testing. Performance testing is the umbrella term for all non-functional tests on the performance of applications. These are tests that look at speed, scalability, and reliability.
Here’s a simple breakdown of three common types of performance tests—spike testing, load testing, and stress testing—and the different purposes they serve.
Load testing is a type of performance testing that’s used to determine how your system performs under different levels of load.
Load tests typically focus on expected load and apply load in a uniform pattern. They’re used to reveal the performance of your site or app performs under expected (or slightly extreme) circumstances.
Say you’re expecting a maximum of 10,000 concurrent users with an average user journey taking 10 minutes. In this scenario, your load test would populate your site with 1,000 virtual users per minute—or maybe 1,100 to push the limits a bit—for 10 minutes.
This lets you understand: (1) whether you can handle 10,000 concurrent users, and (2) whether you can handle a 1,000 new users per minute.
RELATED: Everything You Need To Know About Load Testing
Stress testing is a type of performance testing that focuses not just on the expected load, but on extreme load. Stress tests involve taking your site or app to the breaking point and observing recovery.
This means that if your site works fine at the expected 1,000 users per minute, you’ll keep that bumping up the flow until your system breaks. You might find that things break down once you reach 1,300 users per minute, or 12,000 concurrent users.
This tells you: (1) 1,300 per minute is your maximum throughput, and (2) which bottleneck is preventing you from raising this number higher.
With a stress test, you’re looking to determine where things slow down, produce errors, or crash. It’s about determining the level of load that causes failure, and then investigating how well and fast your system can recover (its recoverability).
RELATED: Load Testing vs. Stress Testing: Key Differences, Definitions & Examples
A spike test in performance testing is the only test that specifically addresses how your system functions during sudden large traffic spikes. Like a load test, it looks at performance under load. But unlike a load test, spike tests apply load to the system suddenly and in large fluctuating numbers.
Instead of 1,000 users per minute for 10 minutes, your spike test might simulate 4,000 users in minute 1, then nothing for 8 minutes, then another 6,000 users in minute 10.
The difference between spike testing and stress testing is that spike tests don’t require you to crash your test environment. The objective of a spike test is to ensure your system can handle (and recover from) a certain amount of traffic and requests coming all at once—not to crash your system.
A spike tests in performance testing is about preparing for the sudden and unexpected.
The key advantage of a spike test is that it reveals how unexpected spikes affect your system and gives you the information you need to avoid an application breaking during such spikes. Below is a spike testing example, compared alongside other types of performance tests.
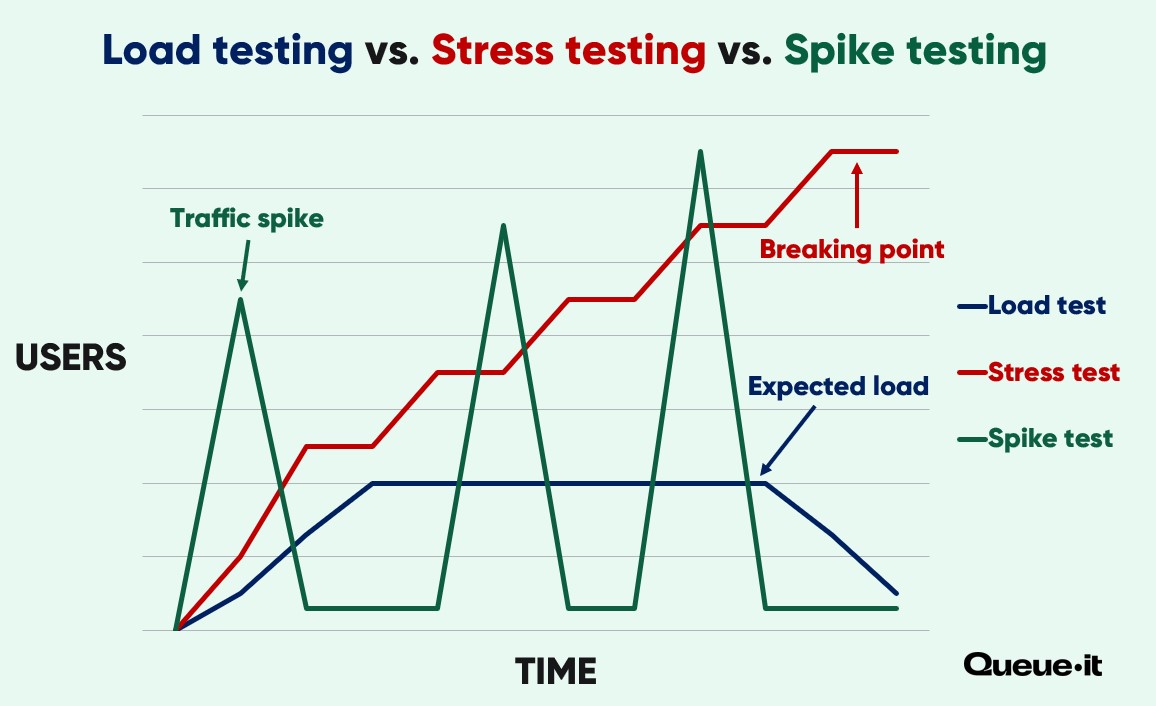
Spike testing vs. stress testing vs. load testing summary: Spike testing, load testing, and stress testing are all performance tests. Load testing applies the expected load to your system to simulate regular (and sometimes extreme) usage. Stress testing takes your system to the breaking point to discover the level of load that causes failure and the system’s recoverability. Spike testing is the only type of performance test that specifically looks at how sudden, dramatic rises and falls in traffic impact performance.
Sudden traffic spikes are more common than most people think. To give you a behind-the-scenes look at real-world web spikes, we’ve gathered traffic data from 4 different high-traffic events run by 4 different companies and organizations. These examples show just how large, sudden, and threatening traffic spikes can be.
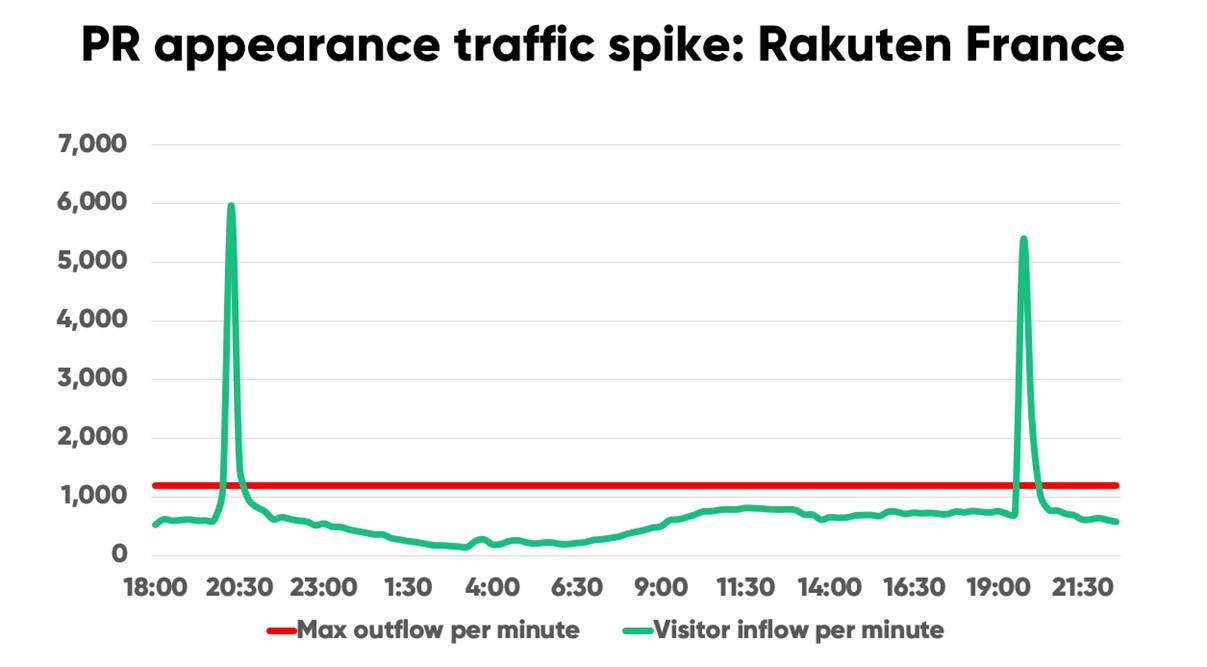
When Rakuten France appeared on national news, traffic to their site spiked 819% in two minutes.
Their traffic threshold—determined by load testing—was 1,200 per minute. Their PR appearances saw traffic 5x that number, hitting 6,000 new users per minute.
“It wasn’t even an ad or offer or anything like that. It just said who our spokesperson worked for and mentioned our brand, and immediately we saw a spike,” Thibaud Simond, Rakuten France’s Infrastructure manager, said.
When cycling brand Rapha teamed up with one of the hottest names in streetwear for a product drop, they knew traffic would be massive.
In the first two hours of the drop, traffic spiked up and down dramatically. Traffic ranged from a couple hundred users per minute to almost 2,000 users per minute.
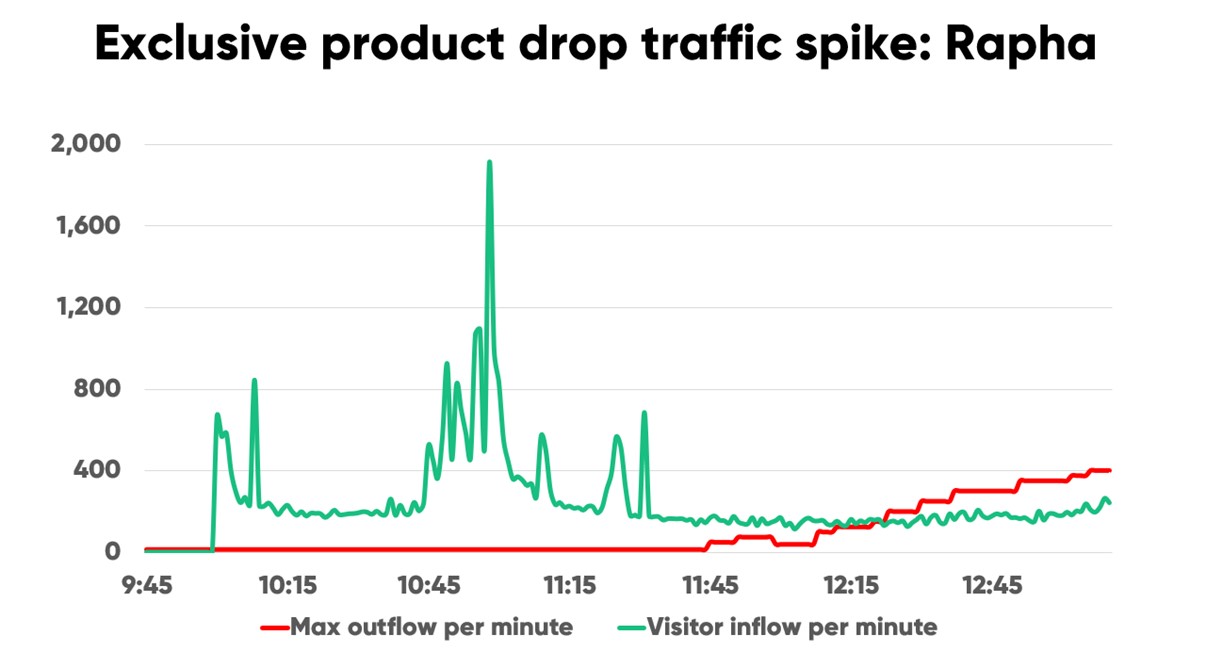
“Our partner only releases using this product drop method. Their whole technology stack is built around selling out—fast. In our first meeting, they disclosed they had seen 100,000 requests every few minutes,” said Rapha’s Engineering Manager Tristan Watson. “Unlike the partner, we work in a more traditional sales model, meaning our infrastructure isn’t designed to deal with the compressed traffic spikes you get during a ‘hyped’ drop.”
RELATED: How Rapha Used a Hyped Product Drop to Reward Loyal Members & Deliver Fairness
Ingresso.com runs ticket sales for Rock in Rio, one of the biggest music festivals in the world. Their most recent onsale had 1 million users in queue to get tickets to the hyped event.
When the general onsale started, traffic spiked to over 20,000 users per minute. Within just 5 minutes, this number dropped by half, staying steady at around 10,000 new users every minute for the next 20 minutes.
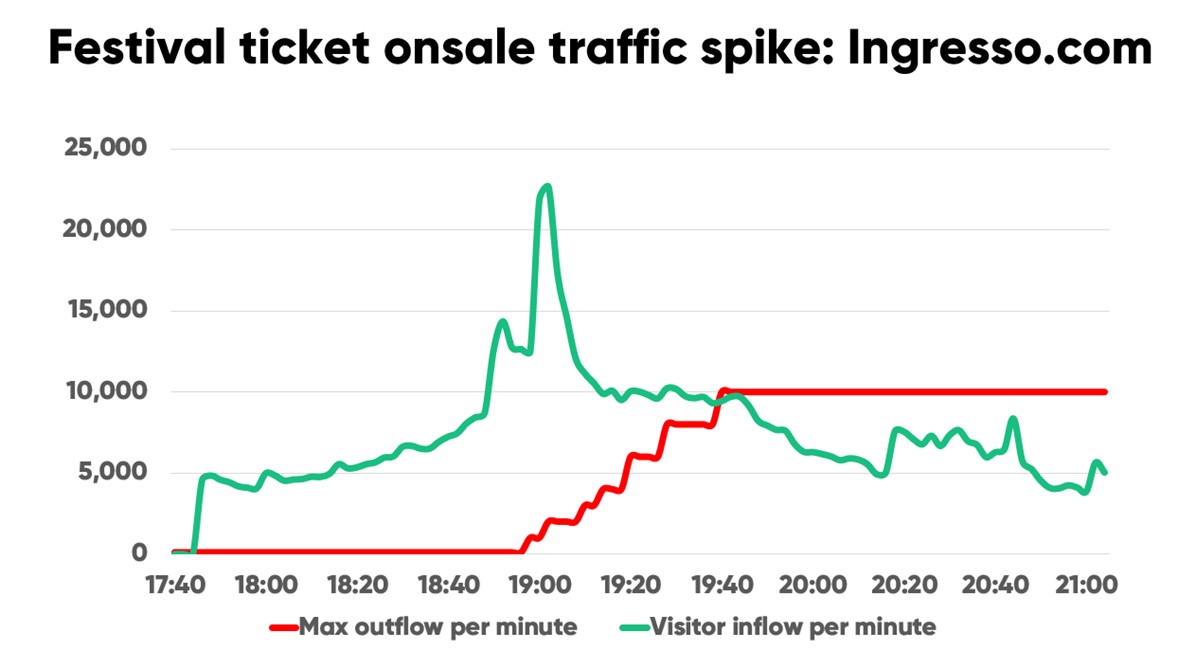
“When you’re in a bull pen, you need something to manage and control the bull. It’s unpredictable and can come rushing at you at any time,” said Ingresso’s CTO Roberto Jose. “Queue-it lets us control the bull that is sudden traffic peaks. It’s not just about selling a lot of tickets—it’s about having more control and safety in what we do.”
RELATED: 1 Million in Queue: How Ingresso.com Delivers on Massive Demand For Rock in Rio
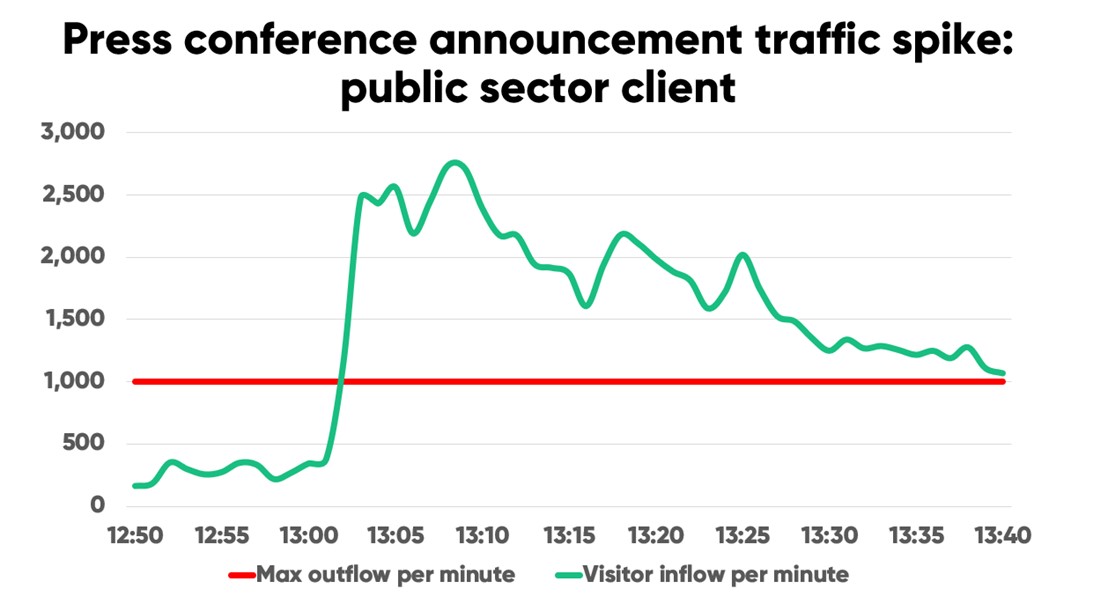
During the height of COVID-19, a public sector client Queue-it works with needed to control traffic spikes caused by press conference announcements. Whenever they made announcements about vaccination registrations or new testing rules in their press conferences, traffic to their site spiked immediately.
In the below example, traffic spiked 525% in just two minutes. We call these public sector traffic spikes the “Press conference effect”.
Most enterprise-level companies and organizations have autoscaling built into their systems.
Put simply, autoscaling means automatically adjusting computing power according to load. It’s “auto”, as in automatic, and “scaling”, as in increasing computing power.
With autoscaling set up right, your server capacity should automatically increase as traffic levels rise. And as traffic decreases, so will your server capacity, saving you cloud computing costs during off-peak times.
RELATED: 3 Autoscaling Challenges & How to Overcome Them With a Virtual Waiting Room
But autoscaling has several limitations when it comes to sudden traffic spikes:
- Autoscaling is reactive, meaning it can take too long to scale in response to load.
- Autoscaling doesn’t address common bottlenecks like payment gateways and database queries.
- If the application hasn't been purpose built for autoscaling, it may not have the elasticity required to autoscale for sudden traffic spikes.
The video below explains in simple terms what autoscaling is and why it hasn't made website crashes a thing of the past.
While load tests and stress tests typically apply load gradually, spike tests apply load suddenly. When load is applied gradually, your application and servers are given time to react and autoscale to handle the load. But a spike test that applies load suddenly might reveal that this reaction doesn’t happen fast enough to handle the traffic spike.
Take the Rakuten France traffic spike mentioned above, for example. Traffic to Rakuten’s website spiked from 500 visitors one minute to 6,000 visitors the next.
If Rakuten ran a load test that gradually increased traffic from 100 visitors per minute to 6,000 visitors per minute over the course of an hour, their systems may have been able to autoscale to handle the traffic. They could look at the results of that load test and say, “We can scale to handle 6,000 visitors per minute, so we’ll be fine.”
But the real spike in web traffic for Rakuten didn’t happen in an hour—it happened in two minutes. A spike test is much better suited to preparing for their situation, because it shows whether their systems can react and scale fast enough to handle massive sudden increases in traffic.
This is what makes spike testing especially useful when using autoscaling: it lets you replicate real-world traffic spikes to look critically at whether your autoscaling set-up can handle them.
"Not all components of a technical stack can scale automatically, sometimes the tech part of some components cannot react as fast as the traffic is coming. We have campaigns that start at a precise hour…and in less than 10 seconds, you have all the traffic coming at the same time. Driving this kind of autoscaling is not trivial."
Alexandre Branquart, CIO/CTO
Spike testing & autoscaling summary: Autoscaling helps your system handle rising traffic levels. But during particularly sudden spikes, autoscaling often can’t react fast enough. Spike testing lets you test the reactivity of your autoscaling and determine whether it can handle the sudden surges in traffic you’re expecting.
Before you even start setting up your spike test, it’s crucial you establish your objectives. You need to be realistic. No website or application can handle unlimited traffic. No site or app can autoscale instantly or infinitely. No site or app can recover immediately.
Your objectives will help determine the metrics you’ll want to track in your spike test. Common metrics you might track include:
- Response time: how long it takes for the application to respond to requests.
- Error responses: the number of requests that produce errors (e.g. 5xx errors codes)
- Throughput: the number of transactions per second.
- Resource utilization: the level of CPU and memory usage.
Say you decide these are the 4 metrics you want to track. You should set your goals for each metric and how they work together.
Ask yourself:
- How many concurrent users should we be able to handle?
- How low should latency to be at this number of users?
- How much CPU and memory are we comfortable using?
- How many transactions per second should we be able to handle?
- How many (if any) errors are acceptable?
- How quickly and effectively can we recover from spikes?
You want to be generous with your estimates and prepare for a worst-case scenario. But you also need to be realistic. Being able to handle massive traffic spikes at lightning-fast speeds takes a lot of work, costs a lot of money, and is sometimes impossible.
It’s important to note that increasing your capacity may start off cheaper and easier. But as the number of concurrent users you want to handle goes up, so will the costs.
Fixing a bottleneck early in the process might just be adjusting a some code or adding a bigger database server. But as your traffic gets larger, so do the challenges. You may need to change your architecture, replace, or change your data models, or even change core business logics and processes.
The second crucial step before your spike tests is that you establish clearly what users are doing on your system. If users aren't all rushing to your site at a precise moment, for example, you mightn't even need to run a spike test (a load test may be better suited).
There’s a big difference between thousands of users sitting on your homepage and thousands of users browsing your site and purchasing items. And the bottlenecks you’re looking to identify in your spike tests are often caused by the latter.
Common site bottlenecks include:
- Payment gateways
- Database queries (e.g. logins, updating inventory databases)
- Building cart objects (add to cart or checkout processes, tax calculation services, address autofill)
- Third-party service providers (authentication services, fraud services,
- Site plugins
- Transactions (e.g. updating inventory databases while processing orders and payments).
- Dynamic content (e.g., recommendation engines, dynamic search & filters)
- CPU usage
When Canadian Health Center NLCHI was facing massive traffic spikes for vaccination certificate registrations, they thought scaling their servers on AWS would help.
But, as Andrew Roberts, the Director of Solution Development and Support told us, “this just brought the bottleneck from the frontend to the backend.”
Similarly, British ecommerce brand LeMieux load tested their site ahead of their biggest Black Friday sale yet. They determined exactly what they could handle, then set up a virtual waiting room and set the outflow from waiting room to site at that rate.
But on the morning of their Black Friday sale, their site experienced significant slowdowns. They realized they’d missed their site search and filter features in their load tests, focusing on traffic volume rather than behavior.
"We believed previous problems were caused by volume of people using the site. But it’s so important to understand how they interact with the site and therefore the amount of queries that go back to the servers."
Jodie Bratchell, Ecommerce & Digital Platforms Administrator, LeMieux
RELATED: LeMieux’s Best Black Friday Yet: “Queue-it saved our website”
It’s important you take a realistic, flow-based approach to spike testing that replicates actual user behavior.
For optimal performance, your site needs to have an average inflow that’s equal to the average outflow.
A flow-based approach to spike testing includes the:
- Typical sequence of pages (e.g., home page, sale page, product page, shopping cart, etc.)
- The estimated time for each action (e.g., how long does it take for customers to get from a product page to payment).
- The most popular workflows (e.g., do most people use dynamic search or product filtering).
This flow-based approach also becomes important during the validation of your results. You can use Little’s Law, from Queuing Theory to ensure that the throughput is accurate.
As Hassan and Jiang write in A Survey on Load Testing of Large-Scale Software Systems: “If there is a big difference between the calculated and measured throughput, there could be failure in the transactions or load variations (e.g., during warm up or cool down) or load generation errors (e.g., load generation machines cannot keep up with the specified loads).”
Once you’ve determined your objectives, understand user behavior and the desired throughput, and have chosen your tool, you should be ready to start your load tests.
The steps of a spike test are typically:
- Create a dedicated test environment that’s identical to the production environment.
- Determine the maximum load you want to handle.
- Apply the maximum load to your application.
- Apply the minimum load to your application.
- Repeat spikes in consistent or random patterns.
- Evaluate performance (under peak load, and minimum load).
- Optimize performance & remove bottlenecks.
- Rinse & repeat until your spike tests meet your objectives.
Here’s a spike testing example to show what your test spikes may look like in your testing tool.
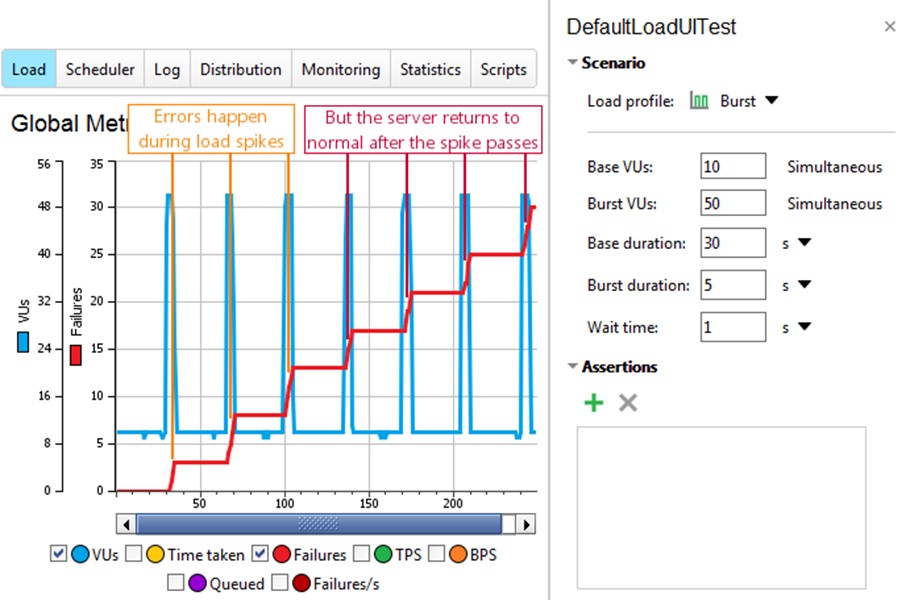
Sudden spikes in traffic are notoriously difficult to handle. If you’ve failed your spike test, you may be looking at one or several of the following challenges:
- You can improve performance, but the solutions are extremely expensive and difficult to implement.
- You can improve performance, but the required changes are not practical to implement for a one-off sale or registration.
- You can improve performance, but won’t be able to implement the necessary changes in time for the high-traffic event.
- The bottlenecks in your system are due to third-party service providers (payment providers, shipping and tax calculators, bot or fraud protection) that can’t increase throughput (or can for an exorbitant price).
- You can’t see any solution; your systems simply can’t handle the number of users they’re expecting.
If you’re facing any of these challenges, there is another solution. It’s fast and easy to implement, doesn’t require significant optimization efforts, and protects your site or app under any level of load.
It’s called a virtual waiting room.
A virtual waiting room gives you control over what other performance optimization efforts can’t: the traffic.
In high-demand situations, websites or apps with a waiting room redirect online visitors to a customizable waiting room using an HTTP 302 redirect. These visitors are then throttled back to your website or app in a controlled, fair order.
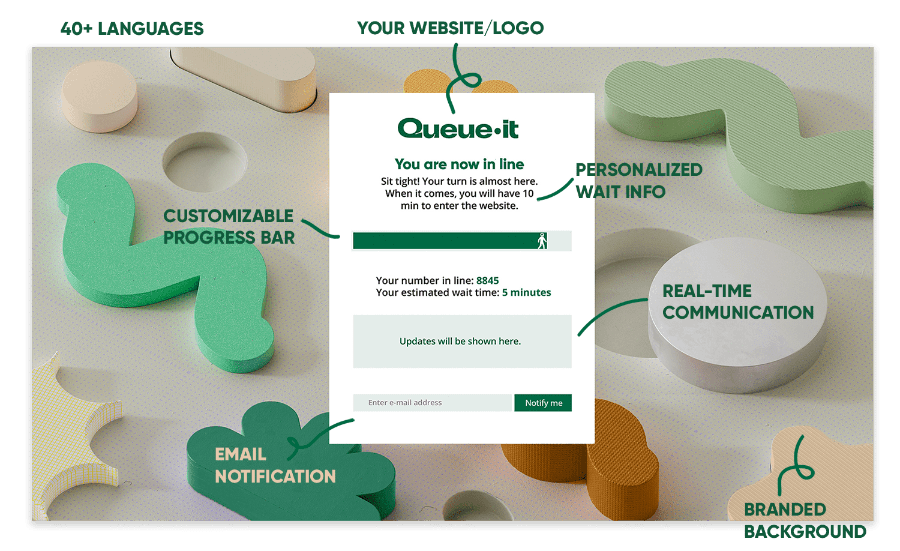
If you’re running a sale or registration that starts at a specific time, you can create a scheduled waiting room that holds early visitors on a countdown page and then randomize them just like a raffle, giving everyone an equal chance. Visitors arriving afterwards are added to the end of the queue on a first-in-first-out basis.
You can control traffic flow down to the minute with a virtual waiting room. Set the traffic outflow from the waiting room to your site to match precisely what your spike tests reveal you can handle—whether it’s a hundred, a thousand, or ten thousand users per minute.
And if unexpected bottlenecks appear in the system, you can reduce traffic flow on the fly.
“Queue-it’s a great bolt-on piece of infrastructure, completely dynamic to our needs. The virtual waiting room made much more sense than re-architecting our systems to try to deal with the insanity of product drops that take place a few times a year.”
Tristan Watson, Engineering Manager, RAPHA
Because the waiting room page is super lightweight, holding users is less resource-intensive than on typical sites or apps.
There’s no updating of inventory databases, or building of cart objects, or bottlenecks related to third-party plugins and payment gateways. This means Queue-it can handle more traffic than even the biggest ecommerce sites.
On an average day, Queue-it processes 100 million visitors. It runs on robust and highly scalable cloud-hosted infrastructure that handles some of the world’s biggest online events.
"The huge server infrastructure mess was something we did not want to continue with. Nobody builds a website to handle hundreds of thousands of people just for a limited amount of time. Throughout the day it’s different, but having that major peak is insane. Queue-it is a great solution that saves the day and it works flawlessly."
Robert Williams, Digital Manager
Essentially, a virtual waiting room handles the massive traffic spikes high-visibility events attract, so you and your engineering team don’t have to.
RELATED: Discover How Load Testing Works with a Virtual Waiting Room [Whitepaper]
- Spike testing is a type of performance testing that involves flooding a site or application with sudden and extreme increases and decreases (spikes) in load.
- Spike testing is important for simulating traffic spikes in a test environment to show how they impact your performance, whether they expose bottlenecks or issues with scalability, and how well your system recovers.
- Spike testing, load testing, and stress testing are three common types of performance tests. Load testing applies the expected load to your system to simulate regular (and sometimes extreme) usage. Stress testing takes your system to the breaking point to discover the level of load that causes failure and the system’s recoverability. Spike testing is the only type of performance test that specifically looks at how sudden and dramatic rises and falls in traffic impact performance.
- Traffic spikes can be expected and unexpected. Common unexpected web traffic spike examples include PR appearances and viral marketing moments. Expected spikes include events like product drops, ticket onsales, and high-profile public sector announcements.
- Autoscaling helps your system handle rising traffic levels. But during particularly sudden spikes, autoscaling often can’t react fast enough. Spike testing lets you test the reactivity of your autoscaling and determine whether it can handle the sudden surges in traffic you’re expecting.
- The spike testing process involves:
- Setting your objectives and benchmarks
- Understanding the user journey
- Choosing your spike testing tools
- Running your spike test
- Using the results to identify and remove bottlenecks
- Repeating until performance meets objectives
- If your spike tests fail and you can’t get performance to where you need it to be, you can use a virtual waiting room to get control over the flow of traffic and prevent errors, slowdowns, or crashes caused sudden surges in traffic.