【解説】アクセス集中時にシステム障害が起こる理由とは?

Eコマースに大きな損失をもたらす、アクセス集中時のシステムダウン。そのダメージを防ぐには、原因を正しく理解し、適切な対策を打つことが大切です。この記事では、トラフィックの急増によってシステム障害が起こる仕組みと、それを防ぐための手立てをご紹介します。
Eコマース事業を行っているほとんどの企業が自社サイトへのアクセス数を上げることを目標としているのではないでしょうか。これは、売上の向上にアクセス数の上昇が大きく関係しているからです。
一方で、きちんとトラフィック対策が練られていない場合、ビジネスに悪影響を及ぼしてしまうこともあります。システムに過負荷がかかるとウェブサイトに不具合が起き、機会損失やそれによる復旧費用が発生するからです。
- 91%の企業が、ダウンタイムによる損失は1時間当たり30万ドル(約4100万円)以上であると報告
- 60%のユーザーが、エラーが出たサイトには戻らないと回答
- 3人中2人の顧客が、読み込みに6秒以上かかるサイトから離脱
では、こういった事態を防ぐにはどうすればよいのでしょうか?この記事では、アクセス集中時にシステム障害が起こる仕組みと、それを回避するための方法をご紹介します。
サイトがダウンする原因は様々ですがよくあるケースとしてはこのような例が挙げられます。
- 人為的ミス (例:Amazonのエンジニアスタッフによる打ち間違いによってインターネットが半壊)
- ネットワークの障害 (例:DynへのDDoS攻撃により、複数の主要サイトがダウン)
- ホスティングパートナーのダウンタイム (例 : デンマークのブラックフライデー期間中、光ファイバーケーブルの修理工事によって2000以上のサイトがダウン)
- サイバー攻撃 (例 : 2022年にウクライナ政府関連の70サイト以上がサイバー攻撃によってダウン)
- アクセス集中 (例:大規模なセール、人気商品の発売や追加販売、キャンペーン実施時などにシステムへ過負荷がかかりサイトがダウン)
この中でも、アクセスが集中するセール、キャンペーンなどは企業にとっては稼ぎ時なので、システム障害は大きな痛手となります。また、こうした人気のイベントはユーザーの期待値が高い分、一度障害が起こると失望も大きくなります。
では、なぜアクセス集中によってシステム障害が起こるのでしょうか。その原因はトラフィックレベルとインフラの容量の不一致です。つまり、ユーザーの行動(ボタンをクリックする、商品をカートに追加する、商品を検索する、パスワードを入力するなど)によるシステムリクエストが、サーバーまたはサードパーティのシステムの処理能力を超えてしまうからです。このGIFのように、無数のユーザーから過度のアクションがあると、インフラ側での処理が追いつかなくなり、システムが不具合を起こしてしまいます。

リクエストはシンプルなものから複雑なものまで様々です。インフラの容量を考える際には、リクエスト量(同時接続ユーザー数)だけではなく、リクエストの種類についても考える必要があります。
スーパーマーケットを例に考えてみましょう。200人が店内に散らばって買い物をしているとします。
レジ係が1分間に処理可能な人数が10人である場合、レジに並ぶ人数がそれ以下である限り、問題は起こりません。
しかし、200人が一斉にレジに並んだ場合はどうでしょうか。店内の人数は変わらないとしても、レジ係の負担が圧倒的に増えます。さらに次の瞬間、一気に800人が新たに店に押し寄せると、全てのバランスが崩れて店内は混乱してしまいます。
アクセス集中が起こっているサイトでは、このスーパーマーケットと同様のことが起こっています。サイト全体をスーパーマーケットに見立てると、ウェブページは店内の通路のようなものです。人々はその間を移動し、商品に関する情報を集めます。
ユーザーがサイト上で商品をカートに追加し、チェックアウトに進むと、データベースでの作業量が増加します。在庫をチェックする、ログイン時にパスワードを確認する、アドレス入力時にサードパーティのプラグインを呼び出す、支払いプロバイダとカードの詳細を確認する、確認メールを送信し、倉庫に情報を転送するなど、複雑なリクエストが続くからです。
このようなシステム上で複数のリクエストが同時に走る混雑ポイントを「ボトルネック」と言います。インフラの容量を考えるときは、ボトルネックの処理能力=インフラ全体の容量だと考えるのが安全です。
一般的なボトルネックの例
- サードパーティの支払いゲートウェイ
- データベースの呼び出し
- 高度な検索機能、ログイン、おすすめ機能などパフォーマンス向上が目的の機能
- 同期プロセス
こうしたボトルネックは、通常なら問題なく稼働しますが、トラフィックが急激に増加するとインフラの許容量オーバーになり、システムをダウンさせてします。だからこそ、アクセス集中によるシステム障害を防ぐにはトラフィックの分散が鍵となります。トラフィックを分散させることで、混雑ポイントの過負荷を回避でき、いつも通りのサイトの運営を行うことができます。
アクセス集中が起こると、ページの読み込みが遅くなります。白い画面のままページが動かなくなるといった経験がある方も多いでしょう。これは、サーバーの役割が、ユーザーにサイトの動的なコンテンツを提供し、リクエスト(在庫チェックと更新、チェックアウト時の支払い処理、アカウントの詳細検証など) を処理することだからです。では、実際にECサイトのサーバーでどのような処理が行われているのか、人気のコスメコレクション販売の例を挙げて考えてみましょう。
| 段階 | ファンの行動 | リクエスト |
|
1 |
ホームページへのリンクをクリック |
画像とブラウザのスクリプトが読み込まれる |
|
2 |
検索バーにほしい製品のアイテム名を入力 |
検索にマッチする全てのアイテムを見つける |
|
3 |
検索結果の商品リストを閲覧し、アイテムをクリック |
画像とブラウザのスクリプトを読み込む、最新の在庫情報を表示する |
|
4 |
アイテムをカートに追加 |
在庫システムを更新し、他のユーザーと完全に同期させてオーバーセルを防ぐ |
|
5 |
ゲストアカウントを作成し、購入ボタンをクリック |
動的に入力された情報を会員データベースと同期する |
|
6 |
配送情報を入力 |
住所確認や送料計算など、配送プラグインからのリクエストを送受信する |
|
7 |
決済情報を入力 |
動的に入力された情報を決済ゲートウェイに送信し、決済の確認を待つ |
|
8 |
注文確認を確認 |
在庫管理システムを更新する |
ユーザー一人当たりで考えると、発生するリクエストの数は8つですが、人気アイテムの販売の場合、数千人が一斉にリクエストを行います。さらに、このリクエストを実行するために、在庫データベース、支払い処理システム、他のサードパーティのプラグインなど、複数のシステムが後方で稼働しています。
これらのステップ全てが、サイトのインフラに負担をかけます。それが処理能力の限界に達してしまうと、リクエストに対応できなくなり、最終的には503エラーページが画面に表示されるのです。
では、アクセスが集中しやすい場面とはどのような状況でしょうか。ここでは典型的な3つの例を紹介します。
これは企業がコントロールできる範囲の外でトラフィックが集中する場合です。例えばインフルエンサーに紹介されSNS上で話題になった、ゴールデンタイムのテレビ番組で特集された、ボットが殺到した、マーケティング施策が予想を超えて成功したといった場面が挙げられます。
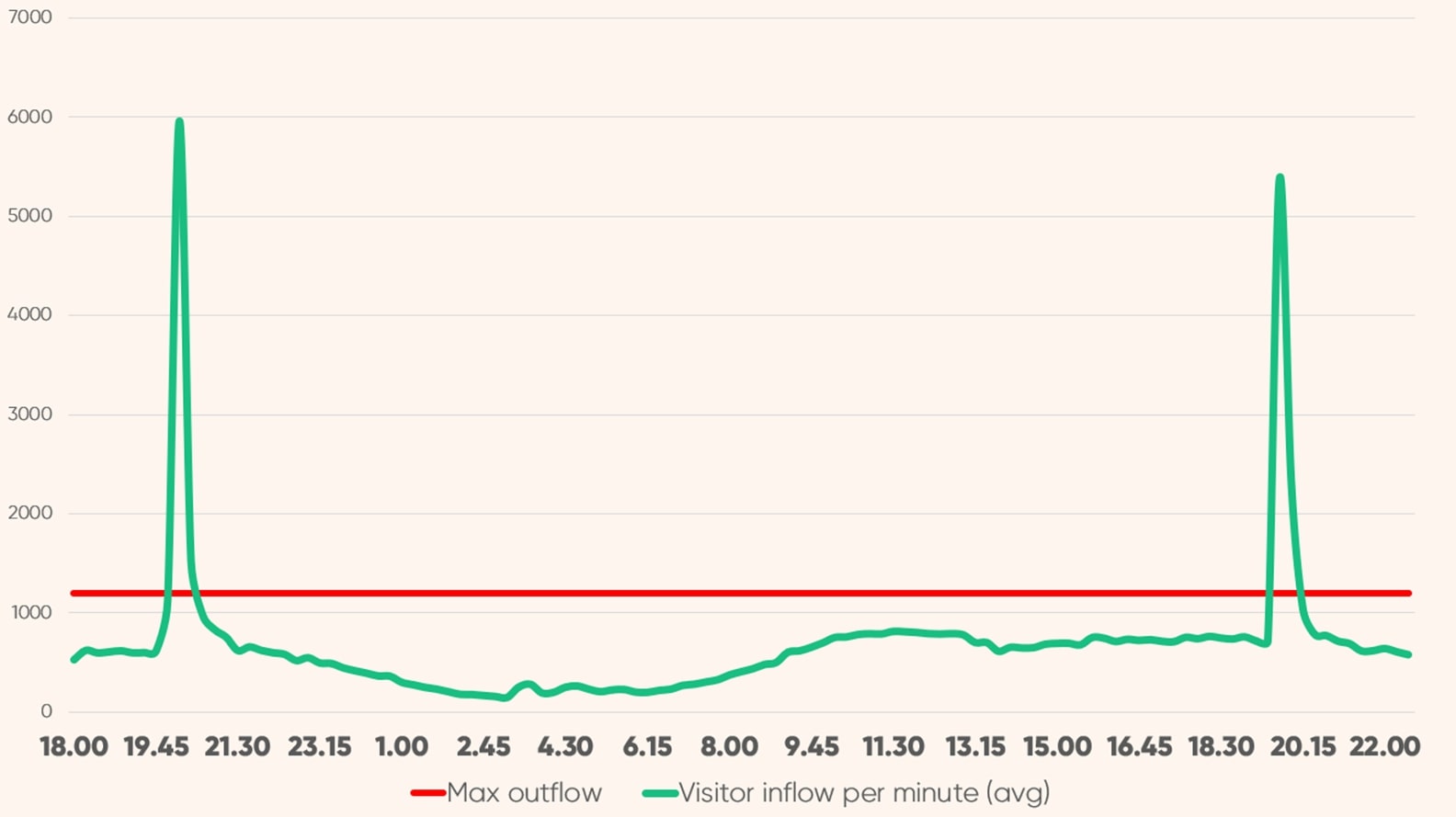
例えば、楽天フランスがテレビで2度報道された直後、同社のサイトにアクセスが819%急増しました。
福袋販売や期間限定セールなど、お得なイベントではアクセス集中がよく起こります。ある報告書によると、こうした発売日のトラフィックは最大で30倍になることもあり、前もって計画されているイベントであっても、タイミングや規模を正確に予測することは困難です。
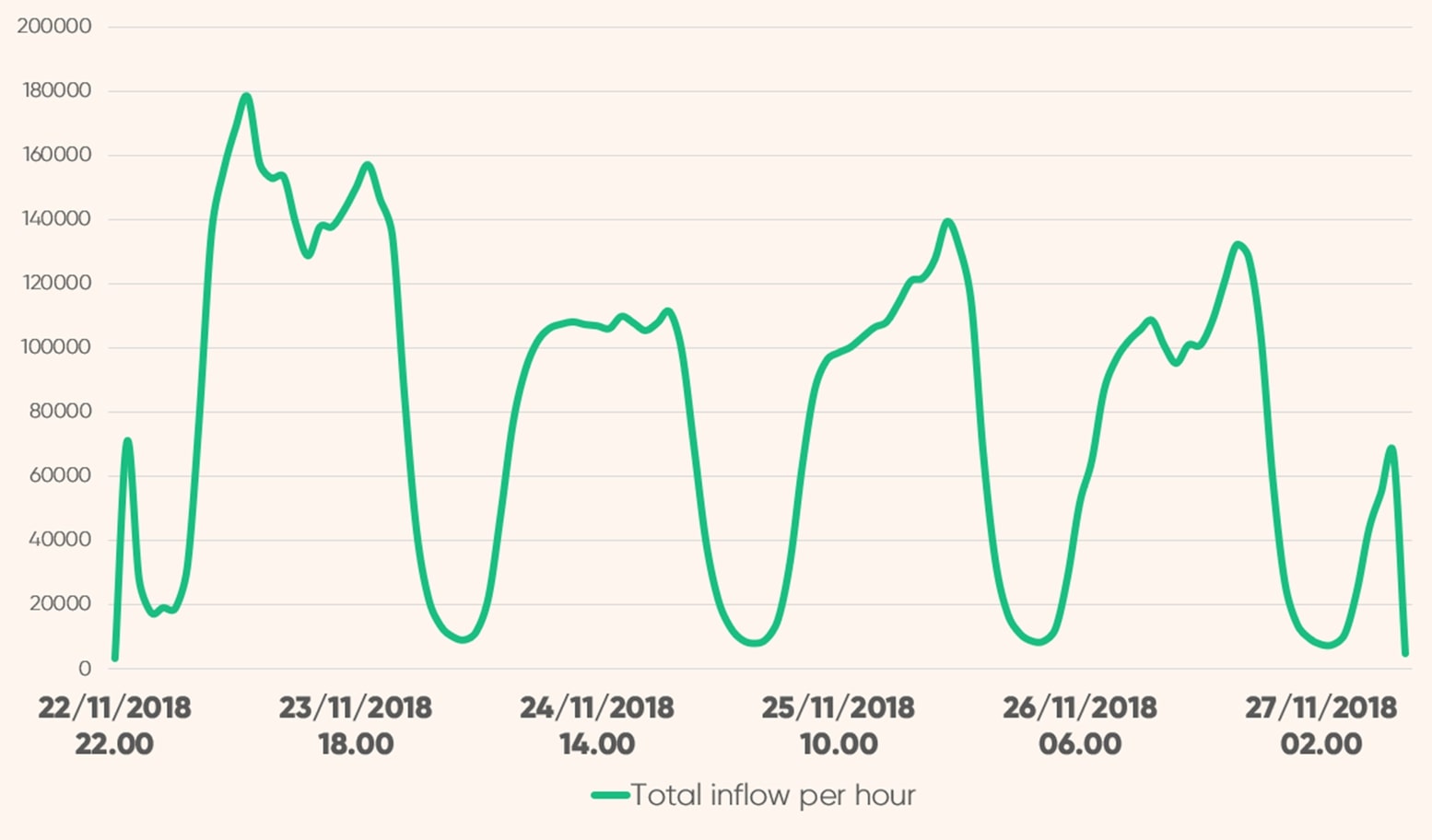
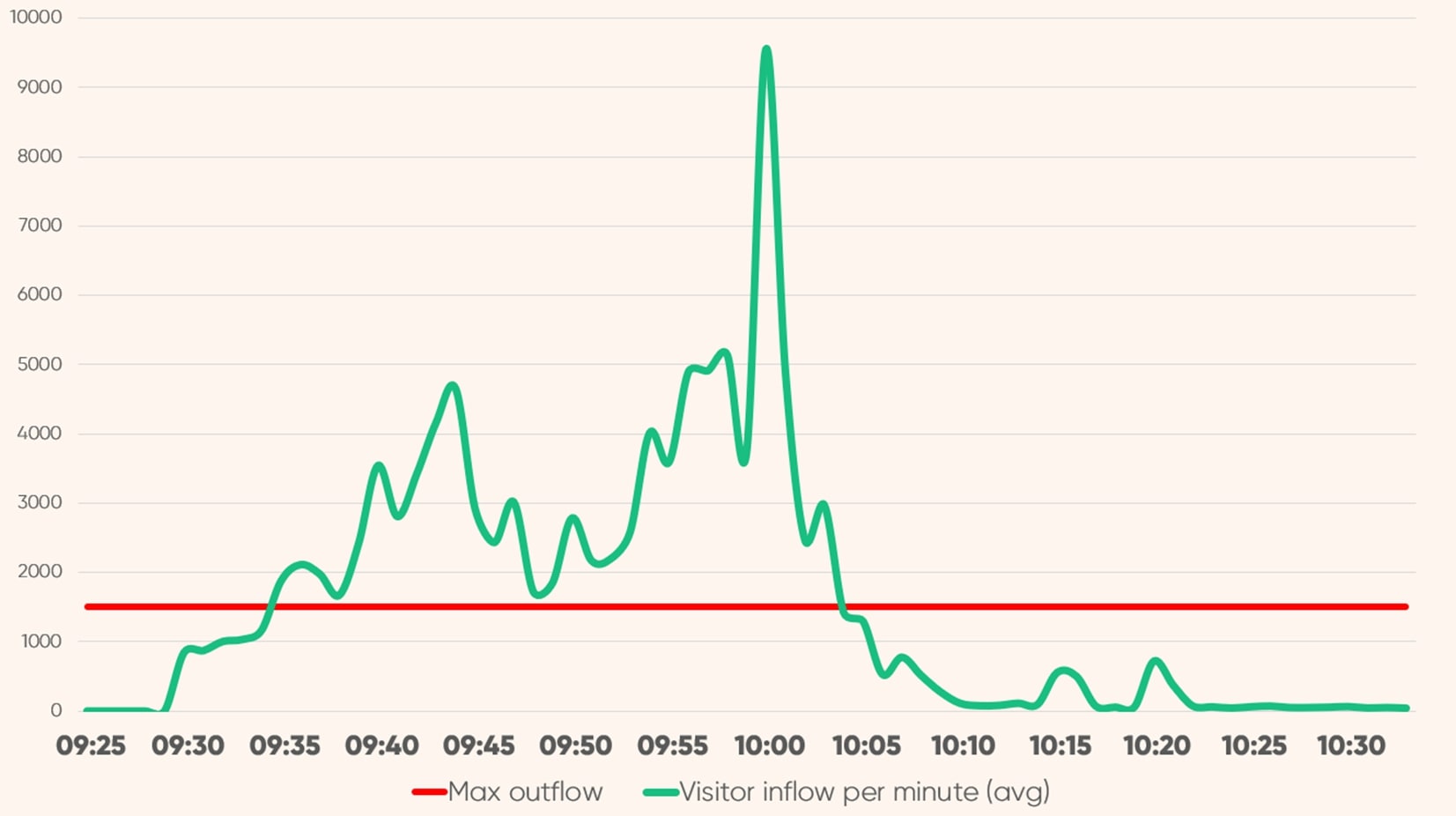
人気アイテムやコラボ商品には熱心なファンがつきもの。こうした商品の販売時は、ほかのファンより少しでも優位に立とうとして開始時間前からサイトにアクセスする人も多く、発売前からサイトがダウンしてしまうこともあります。
こうしたアクセス集中時の障害は、事前の対策で防ぐことができます。しかし対策が不十分だと、ユーザー体験の悪化や商機の損失、リソースの消耗を招いてしまいます。
では、どうすればシステム障害のリスクを最小限に抑えられるのでしょうか?
アクセス障害を防ぐ際にまず欠かせないのが、トラフィックをモニタリングすることです。LogicMonitorの調査によると、モニタリングを積極的に実施しているITチームは、そうではないチームに比べ、ダウンタイムが最も短かったとの結果が出ています。
モニタリングを行うことで、障害をリアルタイムに検知できるほか、自社サイトのトラフィック量とサーバーの容量を正しく理解することもできます。
そして、アクセス集中が原因でシステムに障害が起こった場合は、その都度アプリケーションを分析することも重要です。原因を把握し、次回に備えてシステムを最適化することで、ダウンタイムを削減させることができます。
次に、ボトルネックとなる部分を見直すことも効果的です。例えば下記のような方法があります。
- CDNの導入:お問い合わせやプライバシーポリシーなど、静的コンテンツにまつわるリクエストをCDNで処理することで、サーバーの容量をチェックアウトなどの動的なコンテンツにあてることができます。
- 画像ファイルの圧縮:アップロードするファイルを圧縮し、表示サイズを調整することや、メディアを一度に読み込まず、必要に応じて読み込ませるレイジーローディングを採用することもパフォーマンス向上に繋がります。
- プラグインの使用を最小限にとどめる:プラグインはすぐに古くなるため、CMSやECシステムとの互換性が保てなくなるリスクがあります。
サイトやインフラの容量を理解するためには、モニタリングに加えて負荷テストの実施も有効です。負荷テストは制御された条件下でトラフィックのレベルを増加させるパフォーマンステストのことで、オープンソースのツールを使用すれば無料で行うことができます。
負荷テストは一度きりで完結するものではありません。コードの追加や変更の度に行う必要があり、テスト時は本物のユーザーの挙動をできるだけ再現することが重要です。
実際、サイトの負荷テストを実施したものの、ユーザーの動きが考えられていなかったため、発売日に遅延が発生したというケースもあります。
ユーザーエクスペリエンスを下げるなんて…と思われる方もいるでしょう。ただし、大量のアクセスが予想される場合は、インフラの容量を増やすための手段の一つとなります。
例えば、ダイナミック検索やおすすめ機能など、あると便利ではあっても必須ではない機能などは、アクセス集中が見込まれる時は一時的に停止しても差し支えないでしょう。
また、CPU負荷の高い検索機能から、よりシンプルな検索機能に切り替えることで、データベースの容量も解放できます。
オートスケールは、負荷に応じて自動的かつ一時的に容量を調整することができる機能です。アクセス集中が予測されるときにサーバーを増強することができるため、コスト節約に繋がるとされています。
しかし、オートスケールは万能薬ではありません。例えば、検索機能や決済ゲートウェイなどボトルネックになりやすい部分はオートスケールではカバーしきれません。また、突然のトラフィック急増に対応しきれないなどといった欠点もあります。
サイトの安定した運用のために、ある程度のサーバー増強は効果的ですが、それだけではシステム障害を完全に防ぐことはできません。ボトルネックを解決しないままオートスケールを続けるのは、レジ係の人数と一人当たりの処理能力を変えないままスーパーの広さだけを変えるのと同じことだからです。
人がたくさん集まる店舗や会場で混乱を避ける秘訣は、その場にいる人の動きをコントロールすることです。これをオンライン上で実現したのが仮想待合室です。アクセス数が設定値を超えた場合、それ以降のユーザーは待合室にリダイレクトされ、そこから順番にサイトに案内される仕組みになっています。
仮想待合室があれば、自社インフラのボトルネックや、サードパーティシステムに過度な負荷がかかるのを防ぎ、安定したパフォーマンスで繁忙期でもサイトを安心して運営することができます。
インフラの容量を超えるアクセスが集中すると、サイトやアプリに障害を引き起こします。この記事では、アクセス集中による障害を防ぐために、サイト全体の容量のみでなく、ボトルネックとなる部分の処理能力を把握する重要さ、そして効果的に負荷を軽減する方法についてご紹介しました。人気商品や新製品の発売を企画中の方、予測のつかないアクセス集中でお悩みの方は、この記事を参考に負荷軽減対策を行ってみてくださいね。